



vLLM 0.24.x | 生产就绪 | 2026-07 更新
从本地开发到大规模集群,覆盖参数配置、容器化、监控、安全与性能调优的全流程手册
一、概述与核心优势
vLLM 是加州大学伯克利分校开发的高性能大语言模型推理引擎,核心创新 PagedAttention 借鉴操作系统虚拟内存分页机制管理 KV 缓存,将显存碎片浪费控制在 4% 以内,配合连续批处理(Continuous Batching)技术,吞吐量可达 HuggingFace Transformers 的 10-24 倍。
1.1 核心技术架构
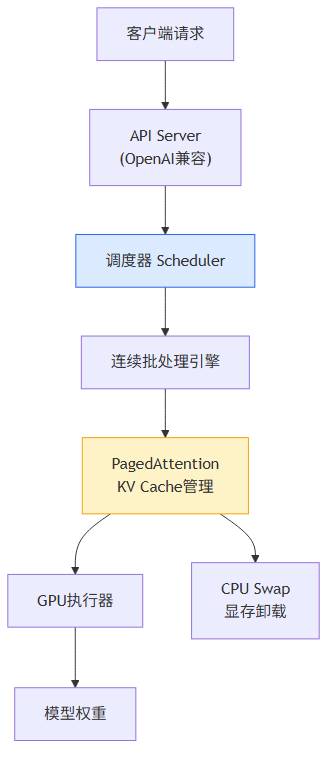
图 1:vLLM 核心架构流程图
1.2 与其他推理框架对比
| 特性 | vLLM | TGI (HF) | TensorRT-LLM | Text Generation Inference |
|---|---|---|---|---|
| 开源协议 | Apache 2.0 | Apache 2.0 | Apache 2.0 | Apache 2.0 |
| PagedAttention | ✅ 原生支持 | ❌ | ⚠️ 有限支持 | ❌ |
| 连续批处理 | ✅ | ✅ | ✅ | ✅ |
| 多卡张量并行 | ✅ | ✅ | ✅ | ✅ |
| LoRA 动态加载 | ✅ | ✅ | ⚠️ | ✅ |
| 推测解码 | ✅ | ❌ | ✅ | ❌ |
| 前缀缓存 | ✅ | ❌ | ❌ | ❌ |
| 多模态支持 | ✅ | ✅ | ⚠️ 有限 | ✅ |
| OpenAI API 兼容 | ✅ | ✅ | ❌ | ✅ |
| 易用性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 性能 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
💡 选型建议:追求极致性能且愿意投入工程成本选择 TensorRT-LLM;快速落地、生态丰富、灵活度高首选 vLLM;HuggingFace 生态深度绑定可考虑 TGI。
1.3 v0.24 新特性与重要变更
vLLM 从 v0.6 到 v0.24 经历了 18 个大版本迭代,以下是需要重点关注的变化:
⚠️ v0.24 Breaking Changes(破坏性变更)
- 设备选择变更:vLLM 不再内部设置
CUDA_VISIBLE_DEVICES,改用新的--device-ids参数指定 GPU。旧的环境变量方式在 ROCm 上已弃用,NVIDIA 端虽仍兼容但推荐迁移。- Transformers v4 弃用:v0.24 目标 Transformers v5,v4 支持已弃用。升级时需同步升级 transformers 库。
- 已移除模型:ERNIE、Xverse、Dots1、Bamba、Mono-InternVL 等模型已从代码库移除。
- 已弃用模型:第一代 Qwen/QwenVL 已标记弃用。
核心新特性
| 特性 | 引入版本 | 说明 |
|---|---|---|
| Model Runner V2 (MRv2) | v0.22+ | 新一代执行引擎,现为 Llama/Mistral/Qwen3/DeepSeek 等模型的默认后端,支持可中断 CUDA Graph、流水线气泡消除 |
| DeepSeek-V4 支持 | v0.22 | 稀疏 MLA、TRTLLM-gen 注意力内核、EPLB 专家负载均衡 |
| DFlash 推测解码 | v0.23 | 新一代推测解码框架,支持因果 DFlash、前缀缓存防损 |
| 多层级 KV Cache 卸载 | v0.23 | 支持对象存储二级层、按请求卸载策略、滑动窗口选择性卸载 |
| 统一解析器引擎 | v0.23 | 推理和工具调用解析统一到单一 Parser.parse() 接口 |
| Rust 前端 | v0.23+ | 实验性高性能前端,支持流式生成、动态 LoRA、API Key 认证 |
| DeepEP v2 专家并行 | v0.24 | 新一代 MoE 专家并行通信库 |
| 扩散大模型支持 | v0.24 | 新增 DiffusionGemma,支持 CPU 路径和结构化输出 |
| EPLB 专家负载均衡 | v0.23 | 异步默认开启,支持 Nixl 零拷贝传输 |
| 安全加固 | v0.24 | 音频解压炸弹防护、推测解码 DoS 防护、正则超时防护 |
二、快速开始
2.1 环境要求
硬件要求:
- NVIDIA GPU:计算能力 ≥ 7.0(V100 及以上)
- 显存:8B 模型 ≥ 16GB,70B 模型 ≥ 80GB(多卡)
- CPU:≥ 16 核,内存 ≥ 32GB
- 存储:SSD,模型文件 ≥ 模型大小 × 2
软件要求:
- CUDA:12.1+(推荐 12.4+ / 13.0)
- Python:3.9 - 3.12
- PyTorch:2.7+(v0.24 推荐 2.11+)
- Transformers:v5.x(v4 已弃用)
- 操作系统:Linux(推荐 Ubuntu 22.04)
- NVIDIA 驱动:≥ 535.xx(CUDA 12.4+需 ≥ 550.xx)
2.2 安装方式
# 方式一:pip 安装(推荐生产环境)
pip install vllm==0.24.0
# 方式二:conda 安装
conda install -c conda-forge vllm
# 方式三:源码编译(最新特性)
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install -e .
# 验证安装
python -c "import vllm; print(vllm.__version__)"
2.3 最小启动示例
# 本地开发快速启动
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--host 127.0.0.1 \
--port 8000 \
--dtype bfloat16
启动后访问 http://localhost:8000/docs 查看自动生成的 OpenAPI 文档。
三、基础配置参数
vLLM 提供 100+ 启动参数,本章详解最核心的基础配置项。
3.1 网络与服务参数
| 参数 | 默认值 | 说明 | 生产建议 |
|---|---|---|---|
--host |
127.0.0.1 | 监听地址 | 0.0.0.0(配合防火墙) |
--port |
8000 | 监听端口 | 根据规划设置 |
--api-key |
- | API 密钥认证 | 生产环境必须设置 |
--ssl-keyfile |
- | HTTPS 私钥路径 | 公网服务必须配置 |
--ssl-certfile |
- | HTTPS 证书路径 | 公网服务必须配置 |
--cors-allow-origins |
- | CORS 允许来源 | 设置具体域名,避免* |
--allowed-origins |
- | WebSocket 允许来源 | 同 CORS 配置 |
--root-path |
- | 应用根路径(反向代理用) | 如 /vllm |
--middleware |
- | 自定义 ASGI 中间件 | 用于限流、审计等 |
--uvicorn-log-level |
info | 日志级别 | warning 减少日志量 |
3.2 模型加载参数
| 参数 | 默认值 | 说明 | 注意事项 |
|---|---|---|---|
--model |
- | 模型名称或本地路径 | 本地路径优先,避免重复下载 |
--tokenizer |
同 model | 分词器路径 | 微调模型需指定对应 tokenizer |
--revision |
main | 模型版本分支 | 生产环境固定版本 |
--dtype |
auto | 模型精度 | A100/H100 用 bfloat16,其他用 float16 |
--quantization |
- | 量化方法 | awq/gptq/fp8/squeezellm |
--max-model-len |
自动探测 | 最大上下文长度 | 根据显存手动设置,避免OOM |
--load-format |
auto | 权重加载格式 | safetensors(推荐)/ pt / np |
--download-dir |
~/.cache/huggingface | 模型下载目录 | 生产环境挂载大容量存储 |
--trust-remote-code |
False | 信任远程代码 | 非官方模型需开启,注意安全 |
--task |
auto | 任务类型 | generate/embedding/classify |
3.3 精度选择指南
✅ 精度选择决策树
- A100/H100/H200/L40 →
bfloat16(首选)- V100/RTX 3090/4090/A10 →
float16- 显存不足 → 优先
AWQ 4bit量化 → 其次FP8 KV Cache- 仅调试用
float32,显存翻倍无性能收益
3.4 量化方法对比
| 量化方式 | 显存节省 | 精度损失 | 推理速度 | 硬件要求 | 推荐场景 |
|---|---|---|---|---|---|
| FP16/BF16 | 0% | 无 | ⭐⭐⭐⭐ | 通用 | 显存充足时首选 |
| FP8 (E4M3) | ~50% | 极小 | ⭐⭐⭐⭐⭐ | H100/RTX40系 | 新硬件首选 |
| AWQ 4bit | ~60% | 极小 | ⭐⭐⭐⭐ | 通用 | 通用量化首选 |
| GPTQ 4bit | ~60% | 小 | ⭐⭐⭐⭐ | 通用 | 已有 GPTQ 模型时 |
| BitsAndBytes 4bit | ~75% | 中等 | ⭐⭐⭐ | 通用 | 显存极度紧张 |
| SqueezeLLM | ~60% | 小 | ⭐⭐⭐ | 通用 | 特定场景 |
四、并行与分布式部署
当模型规模超过单卡显存容量或需要更高吞吐量时,需要使用并行策略。
4.1 三种并行策略详解
张量并行 (TP):--tensor-parallel-size N 或 -tp N
- 将单层模型的权重切分到 N 张卡
- 每张卡持有部分权重,同层计算同步
- 通信量大,需 NVLink 高速互联
- 适合模型层内并行,单节点内使用
- 推荐 N:2/4/8(2的幂次)
流水线并行 (PP):--pipeline-parallel-size N 或 -pp N
- 将模型按层切分到 N 组卡
- 不同组计算不同层,流水线执行
- 通信量小,适合跨节点
- 存在气泡开销,需配合微批处理
- 推荐:100B+ 模型跨节点使用
数据并行 (DP):--data-parallel-size N 或 -dp N
- 复制 N 份完整模型,每份处理不同请求
- 无通信开销,线性提升吞吐量
- 显存占用 N 倍,需 N 倍 GPU 数
- 适合高并发场景,单副本延迟不变
- 注意:vLLM 的 DP 需配合 Ray
专家并行 (EP):--enable-expert-parallel
- MoE 模型专用,将专家分布到多卡
- Mixtral、DeepSeek-V2 等 MoE 必开
- 通常与 TP 配合使用
- 减少单卡专家权重显存占用
4.2 并行策略选择参考
| 模型规模 | 典型模型 | 推荐配置 | GPU 数量 |
|---|---|---|---|
| 1B - 7B | Qwen2.5-7B, Llama3-8B | 单卡 | 1×24GB/40GB |
| 8B - 14B | Llama3-13B, Qwen2.5-14B | 单卡 40GB 或 TP=2 | 1×40GB / 2×24GB |
| 30B - 70B | Llama3-70B, Qwen2.5-72B | TP=4(80GB)或 TP=8(40GB) | 4×80GB / 8×40GB |
| 100B - 200B | DeepSeek-V4, Qwen3-110B | TP=8 + PP=2 | 16×80GB |
| 400B+ | Llama3-405B, DeepSeek-V4-Max | TP=8 + PP=4 + Ray | 32×80GB |
| MoE 8x7B | Mixtral-8x7B | TP=2 + EP | 2×40GB |
| MoE 8x22B | Mixtral-8x22B | TP=4 + EP | 4×80GB |
| 超大 MoE | DeepSeek-V4 (671B) | TP=8 + EP + EPLB | 8×80GB+ |
4.3 分布式后端配置
# 单机多卡(默认,使用 multiprocessing)
vllm serve meta-llama/Llama-3-70b -tp 4
# 多机多卡(使用 Ray 后端)
# 1. 在所有节点启动 Ray
ray start --head --node-ip-address=192.168.1.100 # 主节点
ray start --address=192.168.1.100:6379 # 工作节点
# 2. 启动 vLLM(在主节点)
vllm serve meta-llama/Llama-3-405b \
-tp 8 -pp 4 \
--distributed-executor-backend ray \
--pipeline-parallel-size 4
⚠️ NCCL 网络配置
多机部署时必须配置 NCCL 网络接口,否则可能 hang 住:
export NCCL_SOCKET_IFNAME=eth0(替换为实际高速网卡名),InfiniBand 环境设置export NCCL_IB_DISABLE=0。
五、KV Cache 与显存优化
KV Cache 是影响 vLLM 性能和显存占用的最关键因素,PagedAttention 是 vLLM 的核心竞争力。
5.1 PagedAttention 工作原理
传统推理框架为每个请求预分配连续的 KV Cache 显存,导致严重的内部碎片和外部碎片。PagedAttention 将 KV Cache 分割成固定大小的块(Block),每个块存储固定数量 token 的 K/V 向量,通过页表记录逻辑位置到物理块的映射,与操作系统虚拟内存管理思路一致。
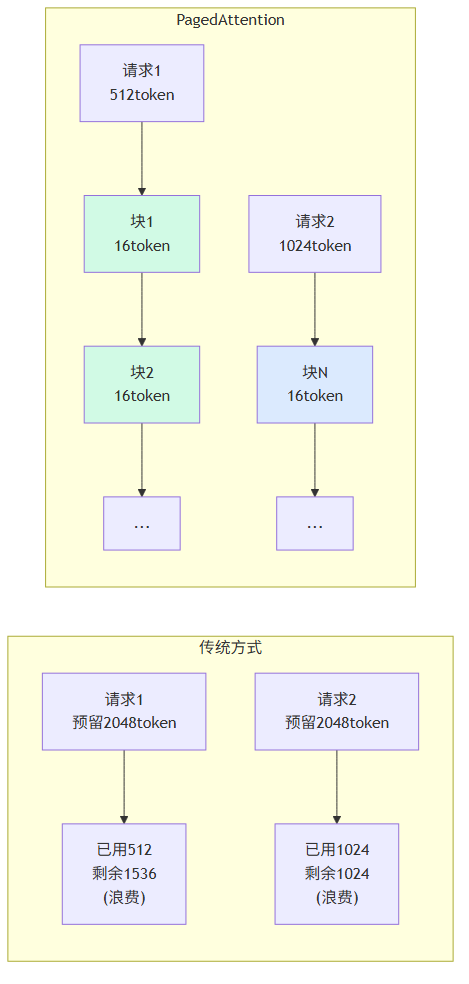
图 2:传统连续分配 vs PagedAttention 分页分配
5.2 KV Cache 核心参数
| 参数 | 默认值 | 说明 | 调优建议 |
|---|---|---|---|
--block-size |
16 | KV 块大小(token 数) | 前缀缓存场景用 16,高吞吐用 32 |
--gpu-memory-utilization |
0.9 | GPU 显存使用比例 | 0.85(稳定)~ 0.95(极限) |
--kv-cache-dtype |
auto | KV 缓存精度 | fp8(省 50% 显存,精度损失小) |
--swap-space |
4 | CPU Swap 大小(GB) | 大模型建议 16~32GB |
--cpu-offload-gb |
0 | CPU 卸载显存(GB) | 显存差 10GB 内可临时用 |
--enable-prefix-caching |
False | 启用全局前缀缓存 | 多轮对话、RAG 场景必开 |
--max-num-batched-tokens |
- | 单步最大 token 数 | 根据模型和显存调整 |
💡 v0.23+ 多层级 KV Cache 卸载
新版本引入了多层级 KV Cache 卸载框架,除了传统的 CPU Swap,还支持对象存储二级层(如 S3)、按请求粒度的卸载策略(
on_new_request生命周期钩子)、以及滑动窗口选择性卸载。大模型可通过 KV Connectors(NixlConnector、LMCache、Mooncake)实现跨实例 KV Cache 传输,支撑分离式 Prefill-Decode 架构。
5.3 前缀缓存(Prefix Caching)
当多个请求共享相同前缀(如系统提示词、RAG 检索的文档开头、多轮对话历史)时,启用前缀缓存可直接复用已计算的 KV 块,避免重复计算,多轮对话场景首字延迟可降低 30%-70%。
# 前缀缓存优化配置
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--enable-prefix-caching \
--block-size 16 \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.9
💡 前缀缓存适用场景
- 多轮对话机器人(共享系统提示词)
- RAG 应用(多个请求共享相同文档前缀)
- 代码补全(共享代码仓库上下文)
- 批量处理任务(共享相同前缀模板)
不适用场景:每个请求完全独立(如独立句子翻译)。
5.4 显存调优步骤
✅ 显存调优四步法
- 设置安全基准:从
--gpu-memory-utilization 0.85开始,确保服务稳定- 逐步提升:每次增加 0.02,观察 10 分钟是否有 preemption 或 OOM
- 开启 FP8 KV:新硬件加
--kv-cache-dtype fp8,再适当提升利用率- 限制并发:如仍不足,调小
--max-num-seqs限制并发序列数监控关键指标:
vllm:gpu_cache_usage_perc保持在 80%-95% 为最佳区间。
六、调度与批处理策略
调度器决定请求如何组批执行,直接决定了吞吐量和延迟表现。vLLM 默认使用 连续批处理(Continuous Batching),这是相比静态批处理的核心优势。
6.1 连续批处理 vs 静态批处理
静态批处理需等批次中所有请求生成结束才能返回,导致"尾巴拖慢整个批次";连续批处理在每个迭代步都可以加入新请求、结束旧请求,GPU 利用率从 30%-50% 提升到 90%+。
6.2 调度核心参数
| 参数 | 默认值 | 说明 | 调优方向 |
|---|---|---|---|
--max-num-batched-tokens |
自动 | 单步迭代总 token 上限 | 高吞吐→大,低延迟→小 |
--max-num-seqs |
256 | 最大并发序列数 | 短对话→大,长文本→小 |
--enable-chunked-prefill |
False | 分块预填充 | 长 prompt 场景必开 |
--max-num-partial-prefills |
1 | 并发预填充数 | 2-4,平衡 TTFT 和生成 |
--scheduling-policy |
fcfs | 调度策略 | fcfs(公平)/ priority(优先级) |
--long-prefill-token-threshold |
4% 上下文 | 长 prompt 阈值 | 根据业务调整 |
--max-long-partial-prefills |
1 | 长 prompt 并发数 | 1,让短请求插队 |
6.3 分块预填充(Chunked Prefill)
长 prompt 场景下,传统做法需等整个 prompt 预填充完成才开始生成第一个 token,导致首字延迟(TTFT)过高。分块预填充将长 prompt 分成多个块,每块预填充后穿插执行生成阶段,显著降低首字延迟。
# 长文本场景配置(长文档总结、RAG)
vllm serve Qwen/Qwen2.5-72B-Instruct \
-tp 4 \
--max-model-len 131072 \
--enable-chunked-prefill \
--max-num-batched-tokens 16384 \
--max-num-seqs 16 \
--max-num-partial-prefills 2
6.4 吞吐量 vs 延迟权衡
🚀 高吞吐量配置(适用:离线批处理、批量推理、非实时任务)
--max-num-batched-tokens 32768
--max-num-seqs 512
--gpu-memory-utilization 0.95
特点:GPU 利用率高,单请求延迟高。
⚡ 低延迟配置(适用:实时对话、交互场景、API 服务)
--max-num-batched-tokens 8192
--max-num-seqs 64
--enable-chunked-prefill
--max-num-partial-prefills 2
特点:TTFT 低,用户体验好。
七、高级功能配置
7.1 LoRA 动态适配器
vLLM 支持在同一基础模型上动态加载多个 LoRA 适配器,无需为每个微调模型启动独立服务,显著节省 GPU 资源。
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--enable-lora \
--max-loras 4 \
--max-lora-rank 64 \
--max-cpu-loras 16 \
--lora-modules \
medical=/data/lora/medical_lora \
legal=/data/lora/legal_lora \
code=/data/lora/code_lora
调用时通过 model 参数指定使用哪个 LoRA:
curl http://localhost:8000/v1/chat/completions \
-H "Authorization: Bearer sk-xxx" \
-H "Content-Type: application/json" \
-d '{
"model": "medical",
"messages": [{"role": "user", "content": "头疼怎么办?"}]
}'
7.2 推测解码(Speculative Decoding)
使用小模型作为"草稿模型"快速猜测多个 token,大模型一次性验证,可在不损失精度的前提下将生成速度提升 2-3 倍。v0.23+ 引入了 DFlash 推测解码框架,支持因果 DFlash 和前缀缓存防损,进一步提升了推测解码的稳定性。
# 推测解码示例
vllm serve meta-llama/Llama-3.1-70B-Instruct \
-tp 4 \
--speculative-model meta-llama/Llama-3.2-1B-Instruct \
--num-speculative-tokens 5 \
--speculative-max-model-len 4096 \
--dtype bfloat16
⚠️ 推测解码注意事项
- 草稿模型必须与目标模型使用相同 tokenizer
- 草稿模型越小、越准,加速效果越好
- 建议
--num-speculative-tokens设为 3-7- 会增加少量显存占用(草稿模型 + 投机 KV)
- v0.24 新增推测解码 token 注入 DoS 防护,提升了安全性
7.3 多模态模型支持
vLLM 支持主流多模态模型:LLaVA、Qwen-VL、Phi-3-Vision、LLaVA-NeXT 等。
# Qwen2-VL 部署示例
vllm serve Qwen/Qwen2-VL-7B-Instruct \
--dtype bfloat16 \
--max-model-len 8192 \
--limit-mm-per-prompt image=4,video=1 \
--mm-processor-kwargs '{"num_crops": 4}'
多模态请求支持两种图片传递方式:URL 和 base64。
7.4 工具调用(Function Calling)
vLLM 0.5+ 原生支持 OpenAI 格式的工具调用,支持经过 function calling 微调的模型(如 Qwen2.5、Llama3.1、FireFunction 等)。
# 支持工具调用的模型无需特殊启动参数,正常启动即可
vllm serve Qwen/Qwen2.5-14B-Instruct \
--dtype bfloat16 \
--max-model-len 32768
启动后即可使用标准 OpenAI tools 格式调用。
7.5 编译优化与 Model Runner V2
vLLM 提供编译优化选项,通过 CUDA Graph 和 Torch Compile 减少 kernel launch 开销,长期运行服务可显著提升性能。v0.22+ 引入了 Model Runner V2 (MRv2) 新一代执行引擎,现为 Llama、Mistral、Qwen3 等主流模型的默认后端,支持可中断 CUDA Graph(breakable CUDA graphs)和流水线气泡消除。
| 优化级别 | 说明 | 启动时间 | 运行性能 | 适用场景 |
|---|---|---|---|---|
| -O0 | 无优化 | 最快 | 基准 | 调试、快速测试 |
| -O1 | 基础 CUDA Graph | 中等 | +10-15% | 默认,平衡启动和性能 |
| -O2 | 更多 CUDA Graph 尺寸 | 较慢 | +15-25% | 生产服务推荐 |
| -O3 | Torch Compile + 全 CUDA Graph | 最慢(编译几分钟) | +25-40% | 长期稳定运行服务 |
# O3 极致优化配置
vllm serve meta-llama/Llama-3.1-8B-Instruct \
-O3 \
--compilation-config '{"mode": 3, "cudagraph_capture_sizes": [1,2,4,8,16,32,64,128]}'
💡 Model Runner V2 说明
v0.24 中 MRv2 已扩展到支持量化模型,并默认启用 GraniteMoE,迁移了 Qwen/DeepSeek-V2 MoE 模型。MRv2 支持 DFlash 推测解码和 FlashInfer 采样器。对于 Llama/Mistral dense 模型,MRv2 自动启用,无需额外配置。如遇兼容性问题,可通过
VLLM_USE_V1=0环境变量临时回退到旧版执行器。
八、Docker 容器化部署
生产环境强烈推荐使用 Docker 部署,避免环境差异问题。
8.1 官方镜像
# 拉取官方镜像(替换对应 CUDA 版本)
docker pull vllm/vllm-openai:v0.24.0
# 支持的镜像标签:
# v0.24.0 (CUDA 12.4)
# latest (跟踪最新 release)
8.2 docker-compose.yml 模板
version: '3.8'
services:
vllm:
image: vllm/vllm-openai:v0.24.0
container_name: vllm-server
runtime: nvidia
ipc: host
ports:
- "8000:8000"
environment:
- VLLM_DEVICE_IDS=0,1,2,3
- NCCL_SOCKET_IFNAME=eth0
- VLLM_WORKER_MULTIPROC_METHOD=spawn
volumes:
- /data/models:/root/.cache/huggingface/hub
- /data/lora:/app/lora
command: >
--model /root/.cache/huggingface/hub/models--meta-llama--Llama-3.1-70b
-tp 4
--dtype bfloat16
--max-model-len 32768
--gpu-memory-utilization 0.9
--kv-cache-dtype fp8
--enable-prefix-caching
--enable-chunked-prefill
--api-key sk-your-production-key
--host 0.0.0.0
--port 8000
-O2
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 120s
logging:
driver: json-file
options:
max-size: "100m"
max-file: "5"
8.3 自定义 Dockerfile
FROM vllm/vllm-openai:v0.24.0
# 安装自定义依赖
RUN pip install --no-cache-dir \
prometheus-client \
langchain \
sentence-transformers
# 复制自定义配置
COPY config.yaml /app/config.yaml
# 健康检查脚本
COPY healthcheck.sh /app/healthcheck.sh
RUN chmod +x /app/healthcheck.sh
EXPOSE 8000
ENTRYPOINT ["vllm", "serve"]
CMD ["--config", "/app/config.yaml"]
九、Kubernetes 部署
大规模生产环境使用 Kubernetes 编排,配合 NVIDIA GPU Operator 实现 GPU 调度。
9.1 前置要求
- Kubernetes 集群 1.26+
- NVIDIA GPU Operator 已安装
- (可选)KubeRay Operator 用于 Ray 集群
- (可选)Prometheus + Grafana 监控栈
9.2 Deployment YAML 示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-llama3-70b
namespace: llm
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: vllm-llama3-70b
template:
metadata:
labels:
app: vllm-llama3-70b
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8000"
prometheus.io/path: "/metrics"
spec:
containers:
- name: vllm
image: vllm/vllm-openai:v0.24.0
command: ["vllm", "serve"]
args:
- "meta-llama/Llama-3.1-70B-Instruct"
- "-tp"
- "4"
- "--dtype"
- "bfloat16"
- "--max-model-len"
- "32768"
- "--gpu-memory-utilization"
- "0.9"
- "--api-key"
- "$(API_KEY)"
- "--host"
- "0.0.0.0"
- "--port"
- "8000"
- "-O2"
ports:
- containerPort: 8000
env:
- name: API_KEY
valueFrom:
secretKeyRef:
name: vllm-secrets
key: api-key
- name: NCCL_SOCKET_IFNAME
value: eth0
- name: VLLM_WORKER_MULTIPROC_METHOD
value: spawn
- name: VLLM_DEVICE_IDS # v0.24+ 推荐方式(替代 CUDA_VISIBLE_DEVICES)
value: "0,1,2,3"
resources:
limits:
nvidia.com/gpu: 4
cpu: "32"
memory: "128Gi"
requests:
nvidia.com/gpu: 4
cpu: "16"
memory: "64Gi"
volumeMounts:
- name: model-cache
mountPath: /root/.cache/huggingface
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 180
periodSeconds: 30
timeoutSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 120
periodSeconds: 10
volumes:
- name: model-cache
persistentVolumeClaim:
claimName: model-cache-pvc
terminationGracePeriodSeconds: 300
---
apiVersion: v1
kind: Service
metadata:
name: vllm-llama3-70b
namespace: llm
spec:
selector:
app: vllm-llama3-70b
ports:
- port: 80
targetPort: 8000
type: ClusterIP
9.3 HPA 弹性伸缩(基于请求队列)
vLLM 暴露 vllm:num_requests_waiting 指标,可配合 Prometheus Adapter 实现基于队列长度的自动扩缩容。
十、生产环境安全加固
10.1 网络安全
🔒 生产环境安全检查清单
- ✅ 始终设置
--api-key,使用强随机密钥- ✅ 公网服务必须配置 HTTPS(
--ssl-keyfile+--ssl-certfile)- ✅ 配置 CORS 时指定具体域名,避免使用
*- ✅ 不要直接暴露 8000 端口到公网,通过 Nginx/Ingress 反向代理
- ✅ 配置 IP 白名单或网络策略限制访问来源
- ✅ 启用防火墙仅放行必要端口
10.2 Nginx 反向代理配置
server {
listen 443 ssl http2;
server_name llm-api.yourcompany.com;
ssl_certificate /etc/nginx/ssl/fullchain.pem;
ssl_certificate_key /etc/nginx/ssl/privkey.pem;
ssl_protocols TLSv1.2 TLSv1.3;
# 限流配置
limit_req_zone $binary_remote_addr zone=llm:10m rate=10r/s;
limit_conn_zone $binary_remote_addr zone=llm_conn:10m;
location / {
limit_req zone=llm burst=20 nodelay;
limit_conn llm_conn 50;
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# SSE 和长连接支持
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_buffering off;
proxy_cache off;
proxy_read_timeout 300s;
}
}
10.3 认证与授权
除了内置的 API Key,生产环境建议:
- 在反向代理层集成统一认证(OAuth2、JWT、企业 SSO)
- 不同业务线使用不同 API Key 并设置限流策略
- 开启请求日志审计
--enable-log-requests - 敏感场景添加请求/响应内容过滤
10.4 v0.24 内置安全加固
v0.24 引入了多项协同安全加固,无需额外配置即可生效:
| 安全特性 | 防护场景 | 说明 |
|---|---|---|
| 音频解压炸弹防护 | 多模态音频输入 | 防止恶意构造的音频文件耗尽内存 |
| 推测解码 DoS 防护 | 推测解码场景 | 防止通过 token 注入进行拒绝服务攻击 |
| 正则超时防护 | 工具调用解析 | 防止恶意正则表达式导致 ReDoS |
| 非有限 temperature 拒绝 | API 请求 | 拒绝 NaN/Inf 等非法 temperature 值 |
| Starlette ≥ 1.0.1 | Web 框架 | 修复 CVE-2026-48710 安全漏洞 |
十一、可观测性与监控
11.1 Prometheus 指标
vLLM 默认在 /metrics 端点暴露 Prometheus 格式指标,无需额外配置。
| 指标名 | 类型 | 说明 | 告警阈值建议 |
|---|---|---|---|
vllm:num_requests_running |
Gauge | 正在处理的请求数 | > max_num_seqs × 0.9 |
vllm:num_requests_waiting |
Gauge | 等待队列长度 | > 10 持续 5 分钟 |
vllm:gpu_cache_usage_perc |
Gauge | KV 缓存使用率 | > 0.98 或 < 0.3 |
vllm:num_preemptions_total |
Counter | 抢占次数 | 增长率 > 1/秒 |
vllm:time_to_first_token_seconds |
Histogram | 首字延迟 | P95 > 2s |
vllm:time_per_output_token_seconds |
Histogram | 每 token 生成时间 | P95 > 0.1s |
vllm:prompt_tokens_total |
Counter | 处理的 prompt token 总数 | 用于统计吞吐 |
vllm:generation_tokens_total |
Counter | 生成的 token 总数 | 用于统计吞吐 |
vllm:avg_prompt_throughput_toks_per_s |
Gauge | Prompt 处理吞吐 | - |
vllm:avg_generation_throughput_toks_per_s |
Gauge | 生成吞吐 | - |
11.2 OpenTelemetry 链路追踪
vllm serve ... \
--otlp-traces-endpoint http://jaeger:4317/v1/traces
11.3 日志配置
--disable-log-stats:关闭控制台详细统计日志(自动化部署建议开启)--enable-log-requests:记录每个请求的详细信息(调试/审计用)--log-level:日志级别(debug/info/warning/error)
十二、性能压测与调优
12.1 官方压测工具
vLLM 提供内置压测工具 vllm bench,可准确测量服务性能。
# 基础压测:随机请求
vllm bench serve \
--host localhost \
--port 8000 \
--model meta-llama/Llama-3.1-8B-Instruct \
--num-prompts 1000 \
--random-input-len 1024 \
--random-output-len 256 \
--max-concurrency 64 \
--api-key sk-xxx
# ShareGPT 数据集压测(更贴近真实对话)
vllm bench serve \
--backend openai \
--host localhost \
--port 8000 \
--dataset-name sharegpt \
--dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json \
--max-concurrency 128
12.2 压测关键指标
| 指标 | 说明 |
|---|---|
| TTFT | 首字延迟,用户最敏感 |
| TPOT | 每输出 token 时间 |
| tok/s | 总吞吐量 |
| RPS | 每秒请求数 |
12.3 系统性调优方法论
✅ 性能调优五步法
- 建立基线:默认配置下压测,记录 TTFT、TPOT、吞吐量作为基准
- 显存优化:调整 gpu-memory-utilization,开启 FP8 KV,开启前缀缓存
- 批处理调优:调整 max-num-batched-tokens 和 max-num-seqs 平衡吞吐延迟
- 开启长文本优化:长 prompt 场景开启 Chunked Prefill
- 编译优化:稳定后开启 O2/O3 编译优化,再次压测对比
十三、YAML 配置文件
生产环境推荐使用 YAML 配置文件管理参数,便于版本控制和环境区分。
13.1 完整配置文件示例
# config.yaml - 生产环境配置示例 (v0.24.x)
model: meta-llama/Llama-3.1-70B-Instruct
tokenizer: null
revision: main
# 设备选择 (v0.24 新参数,替代 CUDA_VISIBLE_DEVICES)
device_ids: 0,1,2,3
# 模型配置
dtype: bfloat16
max_model_len: 32768
quantization: null
load_format: auto
trust_remote_code: false
task: generate
# 并行配置
tensor_parallel_size: 4
pipeline_parallel_size: 1
data_parallel_size: 1
distributed_executor_backend: mp
enable_expert_parallel: false
# KV Cache
block_size: 16
gpu_memory_utilization: 0.9
kv_cache_dtype: fp8
swap_space: 16
cpu_offload_gb: 0
enable_prefix_caching: true
# 调度器
max_num_batched_tokens: 16384
max_num_seqs: 128
enable_chunked_prefill: true
max_num_partial_prefills: 2
scheduling_policy: fcfs
# 网络
host: 0.0.0.0
port: 8000
api_key: sk-your-production-key-change-me
cors_allow_origins:
- https://your-app.com
- https://admin.your-app.com
ssl_keyfile: null
ssl_certfile: null
root_path: null
# LoRA
enable_lora: false
max_loras: 4
max_lora_rank: 64
max_cpu_loras: 16
lora_modules: {}
# 推测解码
speculative_model: null
num_speculative_tokens: 5
# 编译优化
optimization_level: 2
compilation_config:
mode: 2
# 日志
uvicorn_log_level: warning
disable_log_stats: true
enable_log_requests: false
# 可观测性
otlp_traces_endpoint: http://jaeger.monitoring:4317/v1/traces
启动时指定配置文件:
vllm serve --config config.yaml
十四、API 使用与集成
vLLM 完全兼容 OpenAI API 格式,现有基于 OpenAI SDK 的应用几乎无需修改即可切换。
14.1 Chat Completions 接口
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="sk-xxx"
)
# 普通对话
response = client.chat.completions.create(
model="meta-llama/Llama-3.1-8B-Instruct",
messages=[
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "你好,请介绍一下自己。"}
],
temperature=0.7,
max_tokens=512,
stream=True # 流式输出
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
14.2 工具调用示例
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="Qwen/Qwen2.5-14B-Instruct",
messages=[{"role": "user", "content": "北京今天天气怎么样?"}],
tools=tools,
tool_choice="auto"
)
14.3 Embeddings 接口
# 启动嵌入模型
# vllm serve BAAI/bge-m3 --task embedding
# 调用
response = client.embeddings.create(
model="BAAI/bge-m3",
input=["这是一段测试文本", "这是另一段文本"]
)
for emb in response.data:
print(f"文本 {emb.index} 向量维度: {len(emb.embedding)}")
十五、国产 NPU 适配
国产 AI 芯片生态快速成熟,vLLM 已适配主流国产 NPU。
15.1 华为昇腾(Ascend)
适配状态:
- 官方插件:
vllm-ascend - 支持型号:昇腾 910B/950
- 核心功能:PagedAttention、TP、AWQ
- 推荐 CANN 版本:8.0.RC1+
启动示例:
pip install vllm-ascend
vllm serve Qwen/Qwen2.5-7B \
--device npu \
-tp 1 \
--dtype float16 \
--gpu-memory-utilization 0.85 \
--max-model-len 8192
15.2 寒武纪(Cambricon)
- 适配项目:vLLM-MLU(寒武纪官方定制)
- 支持型号:MLU370、MLU590
- 通信库:CNCL(对应 NCCL)
- 注意事项:部分自定义算子需用 BANG C 重写
15.3 海光 DCU
- 技术路线:基于 ROCm 生态,CUDA 兼容性较好
- 支持型号:海光 Z100/Z100L
- 部署方式:使用海光定制 ROCm 编译 vLLM
- 建议:先在测试环境验证所有算子正确性
15.4 其他国产平台
| 厂商 | 产品 | 适配状态 | 备注 |
|---|---|---|---|
| 百度昆仑芯 | 昆仑芯 XPU | 定制版适配 | 百度生态内完善 |
| 阿里平头哥 | 真武系列 | 逐步适配中 | 主流模型已支持 |
| 摩尔线程 | MTT S80 | 适配中 | 基于 CUDA 兼容层 |
| 沐曦 | MX 系列 | 适配中 | 支持主流大模型 |
| 天数智芯 | 天垓系列 | 定制版本 | 支持多种框架 |
十六、故障排查手册
16.1 常见问题诊断
| 问题现象 | 可能原因 | 排查步骤与解决方案 |
|---|---|---|
| CUDA OOM | 1. 并发太高 2. max-model-len 过大 3. KV 缓存不足 | 1. 降低 --max-num-seqs 2. 减小 --max-model-len 3. 开启量化/FP8 KV 4. 降低 --gpu-memory-utilization |
| 首次启动极慢 | 1. 模型下载中 2. CUDA Graph 编译 3. 权重格式转换 | 1. 提前下载模型到本地 2. 降低 optimization-level 3. 首次启动属正常现象,预热后性能稳定 |
| 401 Unauthorized | 1. 未传 API Key 2. Key 错误 3. Header 格式不对 | 检查 Authorization 头格式:Authorization: Bearer sk-xxx |
| 无法外网访问 | 1. host 绑定 127.0.0.1 2. 防火墙拦截 3. 云安全组 | 1. --host 0.0.0.0 2. 检查防火墙/安全组放通端口 3. 确认 Nginx 反向代理配置 |
| 量化模型报错 | 1. 量化格式不匹配 2. 缺少依赖 3. 权重损坏 | 1. 确认模型与 --quantization 参数匹配 2. 安装 autoawq/gptqmodel 等对应库 3. 重新下载模型 |
| 频繁 preemption | KV 缓存不足 | 1. 调高 gpu-memory-utilization 2. 减小 max-num-seqs 3. 开启 kv-cache-dtype fp8 |
| 多卡启动 hang 住 | 1. NCCL 网络配置错误 2. 显卡 P2P 不通 3. 共享内存不足 | 1. 设置 NCCL_SOCKET_IFNAME 2. 检查 nvidia-smi topo -m 3. Docker 加 --ipc=host |
| 生成结果乱码/重复 | 1. tokenizer 不匹配 2. 模型精度问题 3. 量化损失过大 | 1. 确认 tokenizer 与模型对应 2. 尝试 dtype float32 对比 3. 换用精度损失更小的量化方式 |
| TTFT 首字延迟高 | 1. 长 prompt 未开 Chunked Prefill 2. 批处理参数过大 3. 显存不足导致频繁抢占 | 1. 开启 --enable-chunked-prefill 2. 减小 max-num-batched-tokens 3. 检查 preemption 指标 |
| invalid device ordinal | 1. v0.24 设备选择变更 2. CUDA_VISIBLE_DEVICES 不生效 | 1. 使用 --device-ids 参数替代环境变量 2. 或设置 VLLM_DEVICE_IDS 环境变量 3. 确认 GPU 编号与 nvidia-smi 一致 |
| 模型不支持报错 | 1. 使用了已移除的模型(ERNIE/Xverse 等) 2. Transformers 版本不兼容 | 1. 检查模型是否在 v0.24 移除列表中 2. 升级 transformers 到 v5+ 3. 使用替代模型或旧版 vLLM |
16.2 常用诊断命令
# 检查 GPU 状态
nvidia-smi
nvidia-smi topo -m # 检查 GPU 拓扑
# 检查 NCCL
python -c "import torch; print(torch.cuda.nccl.version())"
# 检查 vLLM 版本
python -c "import vllm; print(vllm.__version__)"
# 测试模型加载
python -c "
from vllm import LLM
llm = LLM(model='meta-llama/Llama-3.1-8B-Instruct', dtype='bfloat16')
output = llm.generate('Hello, my name is')
print(output[0].outputs[0].text)
"
# 健康检查
curl http://localhost:8000/health
curl http://localhost:8000/v1/models
16.3 HTTP 错误码说明
| 状态码 | 含义 | 常见原因 |
|---|---|---|
| 200 | 成功 | - |
| 400 | 请求参数错误 | 参数格式错误、缺少必填字段 |
| 401 | 未认证 | API Key 缺失或错误 |
| 404 | 模型不存在 | model 参数错误,或模型未加载 |
| 422 | 参数验证失败 | max_tokens 超过上下文限制等 |
| 429 | 请求过多 | 触发限流(需自行配置中间件) |
| 500 | 服务器内部错误 | 模型推理异常,查看日志 |
| 503 | 服务不可用 | 模型正在加载中 |
十七、场景化配置模板
17.1 智能客服/对话机器人
# 智能客服场景:低延迟 + 多轮对话 + LoRA
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--dtype bfloat16 \
--quantization awq \
--max-model-len 8192 \
--gpu-memory-utilization 0.9 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--block-size 16 \
--enable-chunked-prefill \
--max-num-batched-tokens 8192 \
--max-num-seqs 128 \
--max-num-partial-prefills 2 \
--enable-lora \
--max-loras 4 \
--api-key sk-chatbot-prod \
-O2 \
--host 0.0.0.0 --port 8000
17.2 RAG/长文档处理
# RAG 场景:长上下文 + 分块预填充 + 前缀缓存
vllm serve Qwen/Qwen2.5-72B-Instruct \
-tp 4 \
--dtype bfloat16 \
--max-model-len 131072 \
--gpu-memory-utilization 0.85 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--enable-chunked-prefill \
--max-num-batched-tokens 32768 \
--max-num-seqs 8 \
--max-num-partial-prefills 2 \
--max-long-partial-prefills 1 \
-O2 \
--host 0.0.0.0 --port 8000
17.3 代码补全/生成
# 代码场景:长上下文 + 前缀缓存(代码文件重复度高)
vllm serve deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct \
-tp 2 \
--dtype bfloat16 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--block-size 16 \
--enable-chunked-prefill \
--max-num-batched-tokens 16384 \
--max-num-seqs 64 \
-O2 \
--host 0.0.0.0 --port 8000
17.4 离线批处理/批量推理
# 高吞吐场景:最大化批处理,不关注单请求延迟
vllm serve meta-llama/Llama-3.1-70B-Instruct \
-tp 4 \
--dtype bfloat16 \
--max-model-len 32768 \
--gpu-memory-utilization 0.95 \
--kv-cache-dtype fp8 \
--max-num-batched-tokens 65536 \
--max-num-seqs 512 \
-O3 \
--disable-log-stats \
--host 0.0.0.0 --port 8000
17.5 嵌入模型服务
# Embedding 服务:高并发
vllm serve BAAI/bge-m3 \
--task embedding \
--dtype float16 \
--max-model-len 8192 \
--gpu-memory-utilization 0.9 \
--max-num-batched-tokens 32768 \
--max-num-seqs 512 \
--enforce-eager \
--host 0.0.0.0 --port 8001
17.6 多模态服务
# 多模态:图文理解
vllm serve Qwen/Qwen2-VL-72B-Instruct \
-tp 4 \
--dtype bfloat16 \
--max-model-len 32768 \
--limit-mm-per-prompt image=8,video=2 \
--mm-processor-kwargs '{"num_crops": 8}' \
--gpu-memory-utilization 0.9 \
--enable-prefix-caching \
--enable-chunked-prefill \
--max-num-seqs 32 \
-O2 \
--host 0.0.0.0 --port 8000
17.7 消费级显卡(RTX 4090)
# RTX 4090 24GB 运行 8B 模型
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--dtype float16 \
--quantization awq \
--max-model-len 8192 \
--gpu-memory-utilization 0.88 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--max-num-seqs 64 \
--host 0.0.0.0 --port 8000
17.8 MoE 模型(Mixtral/DeepSeek-V4)
# Mixtral 8x22B(经典 MoE)
vllm serve mistralai/Mixtral-8x22B-Instruct-v0.1 \
-tp 4 \
--enable-expert-parallel \
--dtype bfloat16 \
--max-model-len 32768 \
--gpu-memory-utilization 0.9 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
-O2 \
--host 0.0.0.0 --port 8000
# DeepSeek-V4(v0.24 新增支持,含 EPLB + DeepEP v2)
vllm serve deepseek-ai/DeepSeek-V4 \
-tp 8 \
--enable-expert-parallel \
--dtype bfloat16 \
--max-model-len 131072 \
--gpu-memory-utilization 0.9 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--enable-chunked-prefill \
-O2 \
--host 0.0.0.0 --port 8000
💡 MoE 模型新特性
v0.23+ 为 MoE 模型引入了 EPLB(专家负载均衡),默认异步开启,支持 Nixl 零拷贝传输;v0.24 集成了 DeepEP v2 专家并行通信库,大幅提升大规模 MoE 模型的通信效率。DeepSeek-V4 还支持稀疏 MLA 元数据、TRTLLM-gen 注意力内核等深度优化。
文档说明:本指南基于 vLLM v0.24.x 版本编写。vLLM 迭代极快(约每月一个版本),部分参数在新版本中可能调整或弃用,请以官方文档为准。建议生产环境升级前先在测试环境验证。
vLLM 生产级部署完全指南 | 2026 年 7 月更新