




本文覆盖 MySQL 架构体系、存储引擎源码级原理、索引/事务/锁/MVCC 深度机制、日志系统、SQL 优化、主从复制高可用、生产实战,以及 20 道分层面试题。适用于后端开发、DBA、架构师面试准备。
一、MySQL 整体架构体系
1.1 三层架构总览
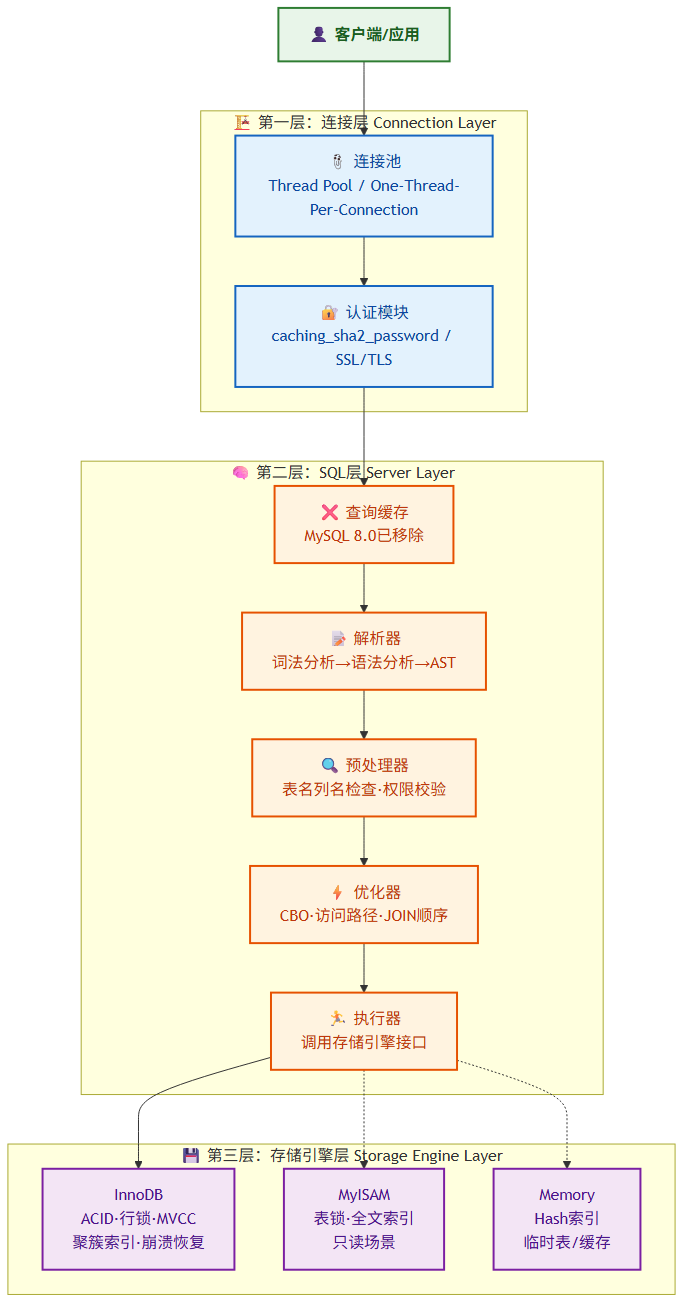
MySQL 采用经典的分层架构,自上而下分为三层:
第一层:连接层(Connection Layer)
负责客户端连接的建立、认证与线程管理。核心组件包括:
- 连接池:维护一组预创建的线程,避免频繁创建销毁。每个连接对应一个线程(
thread_pool/one-thread-per-connection两种模式)。 - 认证模块:校验用户名、密码、Host 白名单。密码使用
caching_sha2_password(MySQL 8.0 默认)或mysql_native_password加密。 - 安全 SSL/TLS:支持 X509 证书认证与通道加密。
第二层:SQL 层(Server Layer)
这是 MySQL 的"大脑",所有跨存储引擎的功能都在这里实现:
- 查询缓存(Query Cache):MySQL 8.0 已移除。原因:命中率极低(任何表变更都导致缓存失效)、并发场景下锁竞争严重、写密集场景反而降低性能。
- 解析器(Parser):词法分析 + 语法分析,将 SQL 文本转换为抽象语法树(AST)。使用 Yacc/Lex 生成。
- 预处理器(Preprocessor):语义检查——表名/列名是否存在、权限校验、
*展开为具体列。 - 优化器(Optimizer):基于成本的优化器(CBO),选择执行计划。核心输出:访问路径(全表扫描 vs 索引扫描)、JOIN 顺序、排序策略。
- 执行器(Executor):调用存储引擎接口执行计划,返回结果集。
第三层:存储引擎层(Storage Engine Layer)
采用插件式架构,不同引擎共享 Server 层但各自实现数据存储与索引。查看命令:
SHOW ENGINES;
SHOW VARIABLES LIKE 'storage_engine';
1.2 InnoDB vs MyISAM vs Memory 对比
| 特性 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 事务支持 | ✅ ACID | ❌ | ❌ |
| 锁粒度 | 行锁/表锁 | 表锁 | 表锁 |
| 外键 | ✅ | ❌ | ❌ |
| 聚簇索引 | ✅ | ❌(堆表) | ❌ |
| 崩溃恢复 | ✅(Redo Log) | ❌ | ❌(数据在内存) |
| MVCC | ✅ | ❌ | ❌ |
| 全文索引 | ✅(5.6+) | ✅ | ❌ |
| 适用场景 | OLTP | 只读/统计 | 临时表/缓存 |
大厂面试核心结论:MySQL 5.5 之后默认引擎为 InnoDB,生产环境几乎所有 OLTP 场景使用 InnoDB。MyISAM 仅在纯只读或归档场景偶有使用。
1.3 一条 SQL 语句的完整执行流程
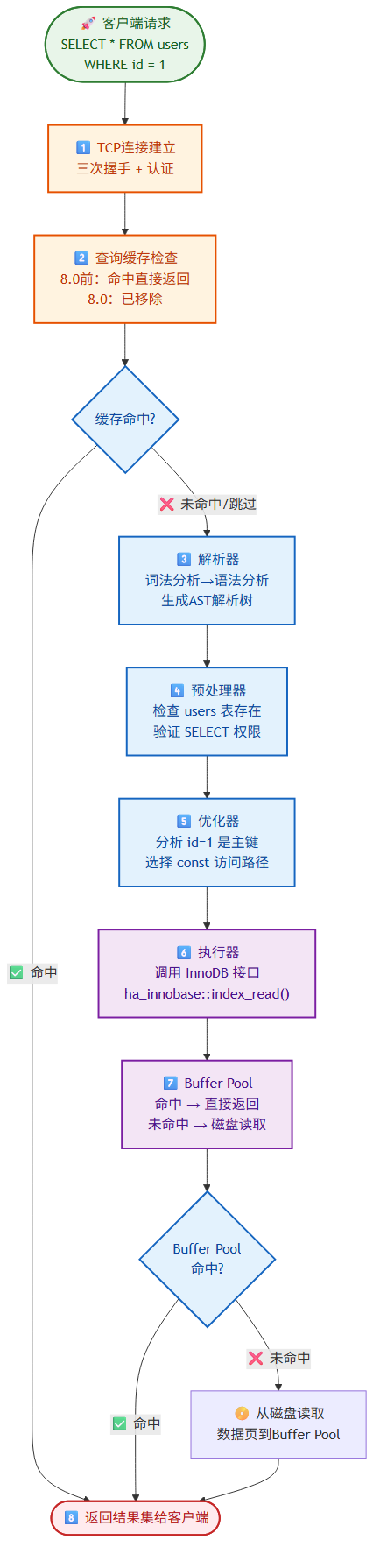
以 SELECT * FROM users WHERE id = 1 为例:
- 客户端与 MySQL 建立 TCP 连接(三次握手),完成认证握手。
- 查询缓存(8.0 前如有)——未命中或已禁用则跳过。
- 解析器生成解析树,检查语法正确性。
- 预处理器检查
users表是否存在、当前用户是否有 SELECT 权限。 - 优化器分析:
id = 1是主键,选择const访问路径(主键等值查询,最快)。 - 执行器调用 InnoDB 引擎接口:
ha_innobase::index_read(),通过 B+树定位到叶子节点。 - Buffer Pool 命中则直接返回,未命中则从磁盘读取数据页到 Buffer Pool。
- 返回结果集给客户端。
SQL 语句执行顺序(面试高频):
FROM → ON → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT
记忆口诀:“F-J-W-G-H-S-O-L”(From-Join-Where-Group-Having-Select-Order-Limit)。
二、InnoDB 存储引擎深度解析
2.1 InnoDB 内存架构
Buffer Pool(缓冲池)——最核心的内存组件
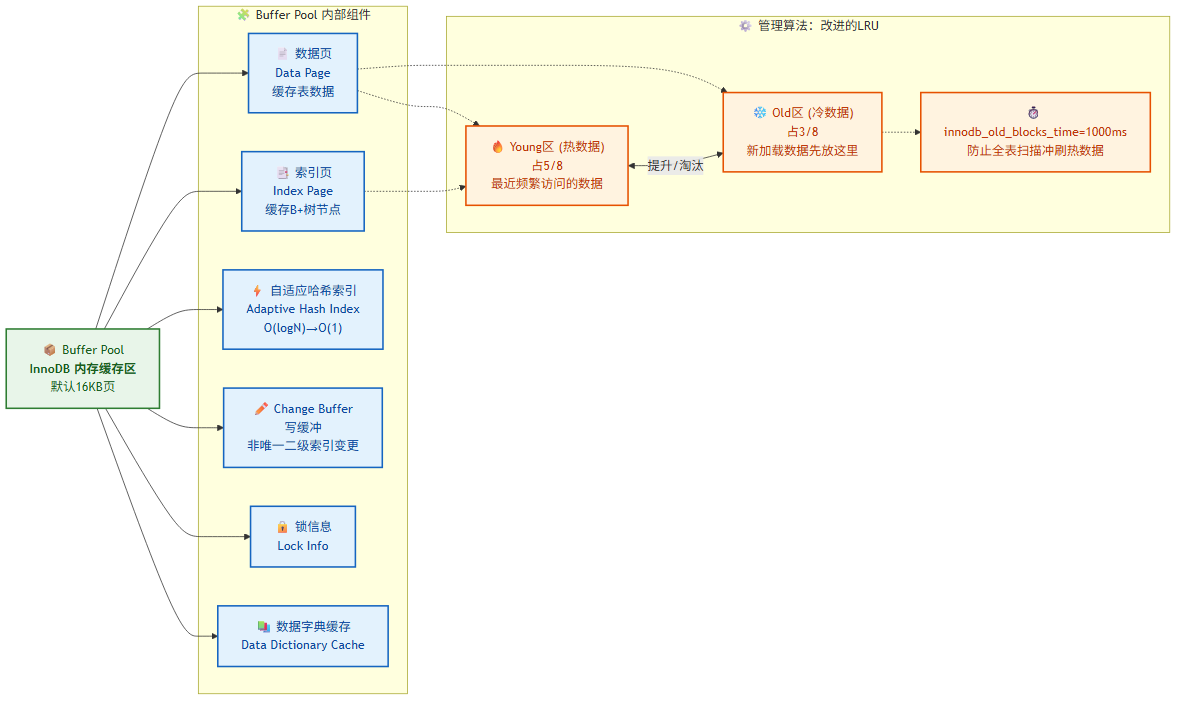
Buffer Pool 是 InnoDB 的内存缓存区,所有读写操作都先经过它。它是理解 InnoDB 性能的关键。
结构(以页为单位,默认 16KB):
Buffer Pool
├── 数据页(Data Page)——缓存表数据
├── 索引页(Index Page)——缓存 B+树节点
├── 自适应哈希索引(Adaptive Hash Index)
├── change buffer(仅对非唯一二级索引页)
├── 锁信息(Lock Info)
└── 数据字典缓存(Data Dictionary Cache)
管理算法——改进的 LRU 算法:
InnoDB 没有使用普通 LRU,而是将 LRU 链表分为两个区域:
- young 区(热数据区,5/8):最近被访问的数据。
- old 区(冷数据区,3/8):新加载的数据先放入这里。
关键参数 innodb_old_blocks_time(默认 1000ms):数据页从 old 区提升到 young 区需要在该页被访问后存活超过这个时间。这防止了全表扫描等一次性操作冲刷热数据。
源码级流程(buf0lru.cc):
1. 读取页时,先查 Buffer Pool
2. 未命中 → 从磁盘加载页 → 插入 old 区头部
3. 若该页在 old 区停留时间 > innodb_old_blocks_time 且再次被访问 → 提升到 young 区头部
4. young 区满 → 从尾部淘汰到 old 区
5. old 区满 → 从尾部淘汰(刷盘或丢弃)
生产调优:
# 物理内存的 60%-80% 分配给 Buffer Pool
innodb_buffer_pool_size = 16G
# 多个 instance 减少锁竞争
innodb_buffer_pool_instances = 8
# old 区占比
innodb_old_blocks_pct = 37
# 防全表扫描冲刷的时间
innodb_old_blocks_time = 1000
# 运行时动态调整大小(5.7.5+)
innodb_buffer_pool_chunk_size = 128M
Change Buffer(写缓冲)
仅对非唯一二级索引的写操作生效。当修改二级索引页不在 Buffer Pool 时,不立即读磁盘,而是先缓存变更。
为什么不对聚簇索引生效?聚簇索引是唯一有序的,必须读取数据页才能定位插入位置。二级索引不一定有序,缓存变更后再合并(merge)即可。
-- 查看 change buffer 使用情况
SHOW ENGINE INNODB STATUS\G
-- 搜索 "INSERT BUFFER AND ADAPTIVE HASH INDEX" 段
Adaptive Hash Index(自适应哈希索引)
InnoDB 自动监控热点查询,如果某个索引页被频繁以相同条件访问,自动构建哈希索引,将 B+树查找 O(logN) 降为 O(1)。
SHOW VARIABLES LIKE 'innodb_adaptive_hash_index'; -- 默认 ON
注意:高并发场景下 AHI 的读写锁可能成为瓶颈,可通过 SET GLOBAL innodb_adaptive_hash_index = OFF 关闭测试。
Redo Log Buffer
事务提交前,Redo Log 先写入内存中的 Redo Log Buffer,再根据刷盘策略写入磁盘。
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
-- 0: 每秒刷盘(性能最好,可能丢1秒数据)
-- 1: 每次提交刷盘(默认,最安全)
-- 2: 每次提交写 OS Cache,每秒 fsync(折中方案)
2.2 InnoDB 后台线程
| 线程 | 功能 | 关键参数 |
|---|---|---|
| Master Thread | 最高优先级,负责调度其他线程、刷新脏页、合并change buffer | innodb_max_dirty_pages_pct |
| IO Thread | 异步 AIO 读写,默认各 4 个读/写线程 | innodb_read_io_threads / innodb_write_io_threads |
| Purge Thread | 回收已提交事务的 Undo Log | innodb_purge_threads (默认4) |
| Page Cleaner Thread | 刷新脏页,减轻 Master Thread 压力 | innodb_page_cleaners (默认4) |
| Checkpoint Thread | 执行 fuzzy checkpoint,推进 LSN | - |
2.3 InnoDB 磁盘结构
表空间(Tablespace)层级:
System Tablespace (ibdata1)
├── 数据字典(Data Dictionary)
├── Doublewrite Buffer
├── Change Buffer
└── Undo Log(5.6前)
File-Per-Table Tablespace (.ibd) ← 默认模式
└── 每张表独立 .ibd 文件
General Tablespace
└── 共享表空间,多表共用
Undo Tablespace (undo_001, undo_002) ← 8.0独立
Temporary Tablespace (ibtmp1)
└── 临时表数据
段(Segment)→ 区(Extent)→ 页(Page)→ 行(Row):
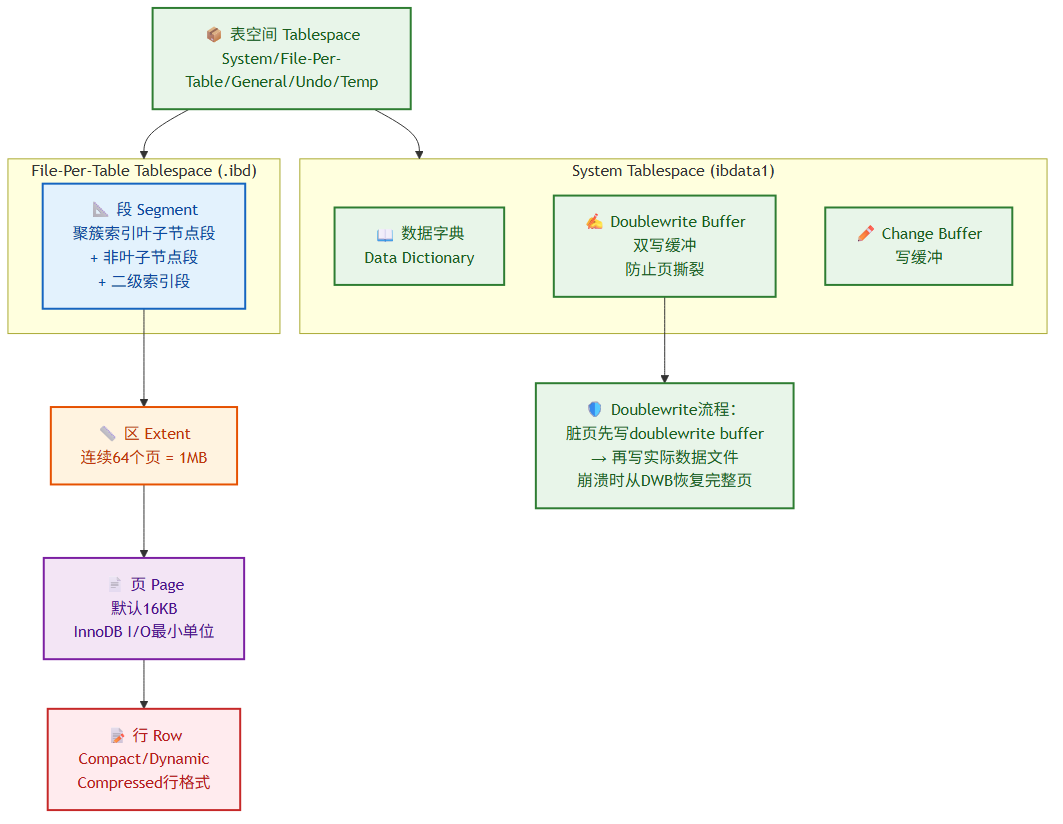
表空间 (Tablespace)
└── 段 (Segment) —— 聚簇索引的叶子节点段 + 非叶子节点段 + 二级索引段
└── 区 (Extent) —— 连续64个页 = 1MB
└── 页 (Page) —— 默认16KB,InnoDB I/O最小单位
└── 行 (Row) —— Compact/Dynamic/Compressed行格式
Doublewrite Buffer(双写缓冲):
防止"页撕裂"(partial page write)问题。16KB 的页在写入 4KB 的文件系统时,如果宕机可能导致只写了一半。恢复时无法用 Redo Log 恢复(因为页本身已损坏)。
流程:脏页刷盘前先写入 doublewrite buffer → 再写入实际数据文件。崩溃恢复时,如果数据页损坏,从 doublewrite buffer 恢复完整页,再用 Redo Log 恢复数据。
SHOW VARIABLES LIKE 'innodb_doublewrite'; -- 默认 ON
三、索引底层原理与优化
3.1 B+树数据结构源码级解析
为什么选择 B+树而不是 B树/红黑树/跳表?
| 数据结构 | 树高度(100万数据) | 磁盘IO次数 | 范围查询 | 适用场景 |
|---|---|---|---|---|
| B+树 | 3-4层 | 3-4次 | ✅高效 | 数据库索引 |
| B树 | 5-6层 | 5-6次 | ❌需中序遍历 | 文件系统 |
| 红黑树 | ~20层 | 20次 | ❌ | 内存数据结构 |
| 跳表 | ~15层 | 15次 | ✅ | Redis ZSet |

InnoDB B+树分析(默认页大小 16KB):
假设主键为 BIGINT(8字节),指针 6字节。每个非叶子节点可存储 16KB / (8+6) = 1170 个键值对。叶子节点存储完整行数据,假设每行 1KB,则每个叶子页可存储 16 行。
三阶 B+树可存储数据量:1170 × 1170 × 16 ≈ 2190万行,只需 3 次 IO 即可定位。
InnoDB B+树源码关键文件:
storage/innobase/btr/
├── btr0btr.cc —— B+树创建、搜索、插入
├── btr0cur.cc —— 游标操作(定位、插入、删除)
├── btr0pcur.cc —— 持久游标
└── btr0sea.cc —— 自适应哈希索引
关键函数链(索引查找):
btr_pcur_open() // 打开B+树游标
└── btr_cur_search_to_nth_level() // 从根节点逐层搜索
├── page_check_dir() // 检查页目录
├── page_rec_binary_search() // 页内二分查找(Page Directory中的槽位)
└── btr_page_get_father_block() // 获取父节点
3.2 聚簇索引 vs 二级索引
聚簇索引(Clustered Index):
InnoDB 的聚簇索引将数据和索引存在同一个 B+树中,叶子节点直接存储完整行数据。一张表只能有一个聚簇索引,默认是主键。
如果表没有主键,InnoDB 选择第一个 NOT NULL 的唯一索引;如果也没有,则自动生成一个 6 字节的 ROW_ID 作为隐藏主键(GEN_CLUST_INDEX)。
二级索引(Secondary Index):
二级索引的叶子节点存储的是索引列值 + 主键值,而不是完整行数据。查询需要回表(Bookmark Lookup):
1. 通过二级索引B+树定位到主键值
2. 通过主键值在聚簇索引B+树中定位完整行
覆盖索引(Covering Index):如果查询的列全部包含在二级索引中,不需要回表,直接返回索引中的数据。执行计划显示 Using index。
-- 联合索引 (name, age)
SELECT name, age FROM users WHERE name = '张三'; -- 覆盖索引,不回表
SELECT * FROM users WHERE name = '张三'; -- 需要回表
3.3 联合索引与最左前缀原则
联合索引 (a, b, c) 在 B+树中按照 a → b → c 的顺序排列。最左前缀原则意味着:
-- ✅ 能命中索引
WHERE a = 1
WHERE a = 1 AND b = 2
WHERE a = 1 AND b = 2 AND c = 3
WHERE a = 1 AND b > 2 -- a走索引,b走索引,c不走(范围之后失效)
WHERE a = 1 ORDER BY b -- 索引天然有序,无需额外排序
-- ❌ 不能命中索引
WHERE b = 2 -- 缺少最左列a
WHERE b = 2 AND c = 3 -- 缺少最左列a
WHERE c = 3 -- 缺少最左列a
-- ⚠️ 部分命中
WHERE a = 1 AND c = 3 -- a走索引,c不走索引(中间跳过了b)
索引下推(Index Condition Pushdown, ICP)——MySQL 5.6 引入:
在没有 ICP 之前,对于 WHERE a = 1 AND c LIKE '%xyz',存储引擎通过索引查出所有 a = 1 的记录的主键,全部回表,然后在 Server 层过滤 c LIKE '%xyz'。
有了 ICP 后,c LIKE '%xyz' 条件下推到存储引擎层,在索引层面就过滤掉不满足条件的记录,减少回表次数。
-- 查看是否使用 ICP
EXPLAIN SELECT * FROM t WHERE a = 1 AND c LIKE '%xyz';
-- Extra 列显示 "Using index condition" 表示使用了ICP
3.4 索引失效场景全总结

-- 1. 对索引列使用函数或表达式
WHERE YEAR(create_time) = 2024 -- ❌ 函数导致索引失效
WHERE create_time >= '2024-01-01' -- ✅ 改写为范围查询
-- 2. 隐式类型转换
WHERE phone = 13800138000 -- ❌ phone是VARCHAR,传入INT导致隐式转换
WHERE phone = '13800138000' -- ✅ 类型匹配
-- 3. 模糊查询以%开头
WHERE name LIKE '%张' -- ❌ 无法利用索引有序性
WHERE name LIKE '张%' -- ✅ 可以利用索引
-- 4. OR连接的条件有一侧无索引
WHERE a = 1 OR b = 2 -- 如果b无索引,整个查询走全表扫描
-- 5. 联合索引不满足最左前缀
WHERE b = 2 AND c = 3 -- 跳过了a,索引失效
-- 6. NOT IN / NOT EXISTS / != / <>
WHERE status != 1 -- 通常走全表扫描(优化器成本评估)
-- 7. IS NOT NULL(某些版本)
WHERE col IS NOT NULL -- 8.0已优化,可用索引
-- 8. 优化器认为全表扫描更快(表数据少 或 选择的列太多)
-- 解决:FORCE INDEX(idx_name)
3.5 索引创建原则与实战
什么时候建索引:
- 主键必建(聚簇索引)
- 外键关联字段
- 经常作为 WHERE / JOIN / ORDER BY / GROUP BY 条件的列
- 区分度高的列(
SELECT COUNT(DISTINCT col) / COUNT(*) FROM table,>0.3 考虑) - 覆盖高频查询的所有列(避免回表)
什么时候不建索引:
- 数据量小的表(<1000行)
- 频繁更新的列(维护索引开销大)
- 区分度低的列(如 gender 只有男/女)
- WHERE 中从不使用的列
索引优化实战:
-- 冗余索引检测(pt-duplicate-key-checker)
-- (a,b) 和 (a) 是冗余的,因为(a)是(a,b)的最左前缀
-- 未使用索引检测
SELECT * FROM sys.schema_unused_indexes;
-- 索引使用统计
SELECT * FROM sys.schema_index_statistics;
-- 强制使用索引
SELECT * FROM users FORCE INDEX(idx_name) WHERE name = '张三';
-- 忽略索引
SELECT * FROM users IGNORE INDEX(idx_name) WHERE name = '张三';
四、事务与 MVCC 机制
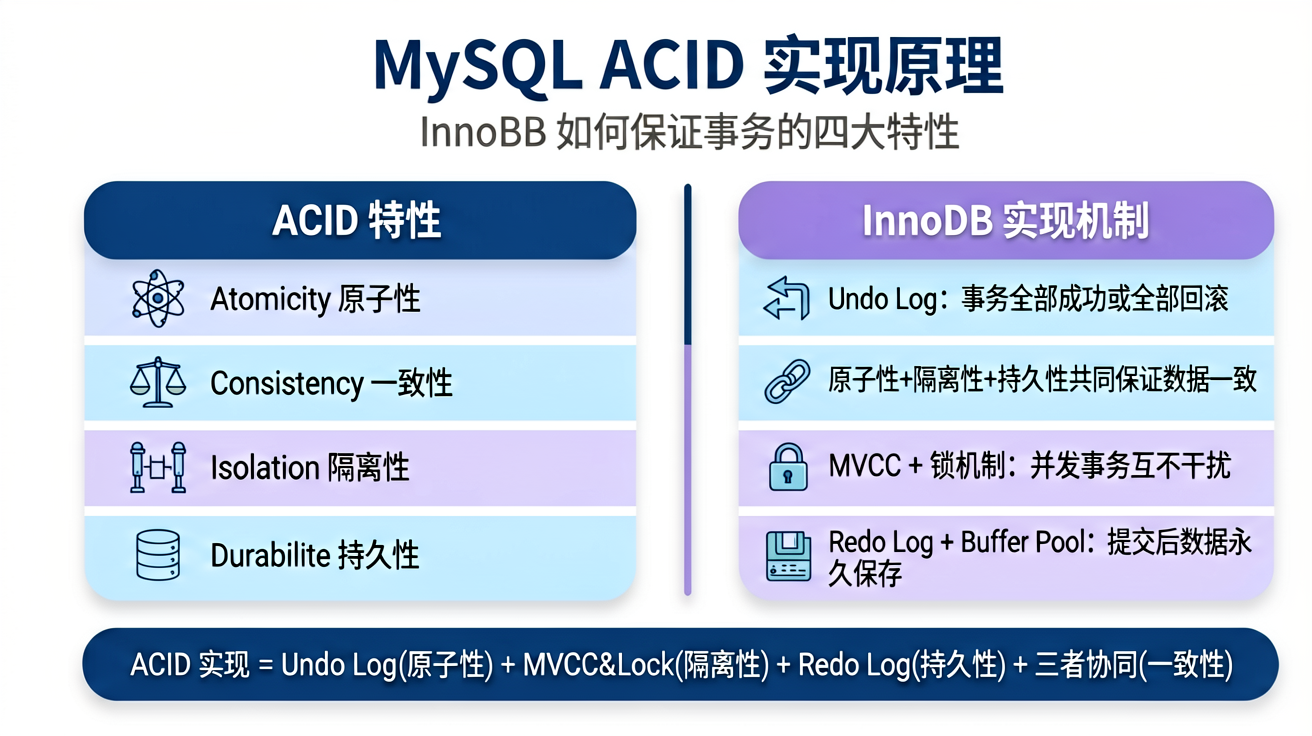
4.1 ACID 实现原理
| 特性 | 含义 | InnoDB 实现 |
|---|---|---|
| Atomicity 原子性 | 事务要么全部成功,要么全部回滚 | Undo Log |
| Consistency 一致性 | 事务前后数据状态一致 | 原子性+隔离性+持久性共同保证 |
| Isolation 隔离性 | 并发事务互不干扰 | MVCC + 锁 |
| Durability 持久性 | 事务提交后数据永久保存 | Redo Log + Buffer Pool |
4.2 事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | InnoDB默认 |
|---|---|---|---|---|
| READ UNCOMMITTED 读未提交 | ✅ | ✅ | ✅ | |
| READ COMMITTED 读已提交 | ❌ | ✅ | ✅ | |
| REPEATABLE READ 可重复读 | ❌ | ❌ | ❌(InnoDB) | ✅ |
| SERIALIZABLE 串行化 | ❌ | ❌ | ❌ |
三种读异常:
- 脏读:读到其他事务未提交的数据。
- 不可重复读:同一事务中两次读同一行数据,结果不同(其他事务已提交的修改)。
- 幻读:同一事务中两次范围查询,结果集行数不同(其他事务已提交的插入/删除)。
InnoDB 在 RR 级别下通过 Next-Key Lock 解决了幻读问题,这是 InnoDB 区别于标准 SQL 的地方。
-- 查看当前隔离级别
SELECT @@transaction_isolation;
-- 设置隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
4.3 MVCC 多版本并发控制源码级解析
MVCC(Multi-Version Concurrency Control)是 InnoDB 在 RC 和 RR 隔离级别下实现非锁定读的核心机制。
隐藏列:
InnoDB 每行数据都有两个隐藏列:
| 隐藏列 | 大小 | 说明 |
|---|---|---|
DB_TRX_ID |
6字节 | 最近修改本行的事务ID |
DB_ROLL_PTR |
7字节 | 回滚指针,指向 Undo Log 中的上一版本 |
DB_ROW_ID |
6字节 | 隐藏主键(无显式主键时使用) |
Undo Log 版本链:
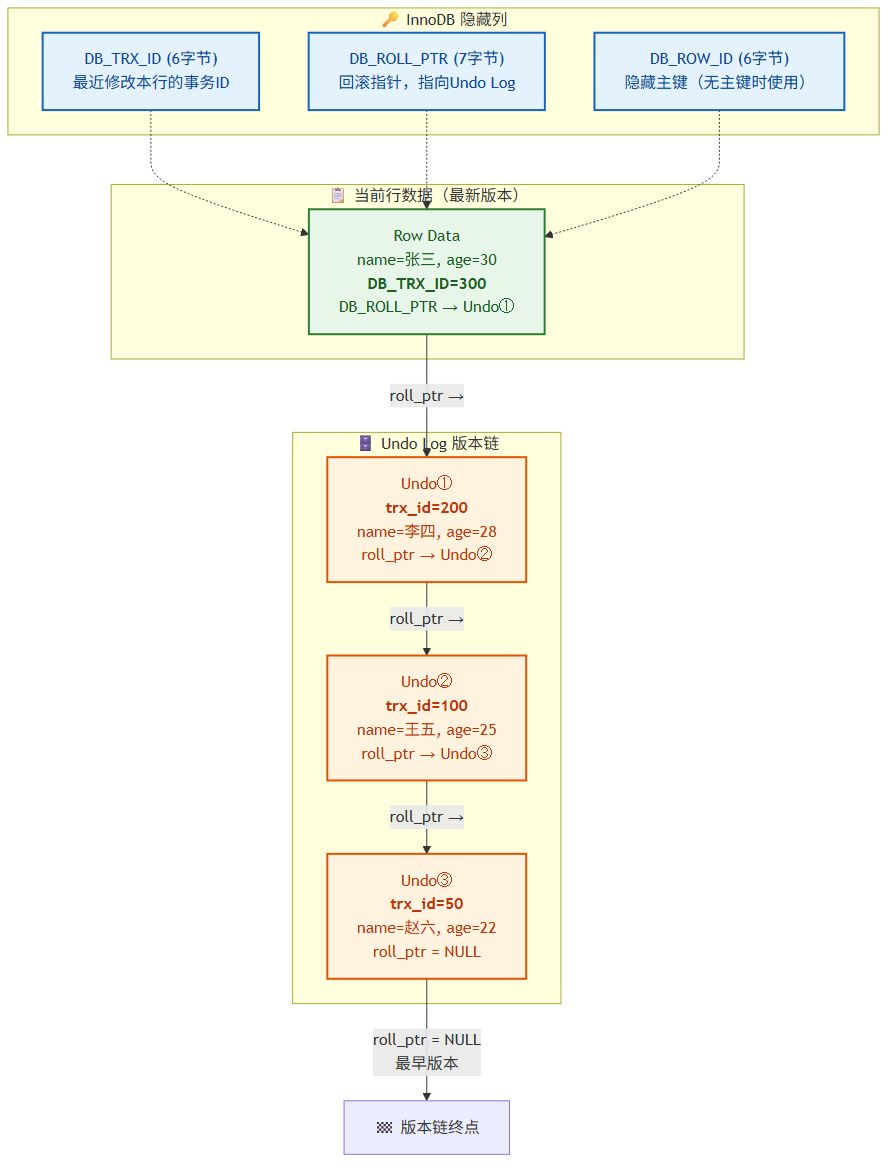
每次修改一行数据,旧版本通过 DB_ROLL_PTR 串联起来形成版本链:
当前行 [trx_id=300, roll_ptr→]
↓
Undo Log: [trx_id=200, roll_ptr→]
↓
Undo Log: [trx_id=100, roll_ptr=NULL]
ReadView(读视图)——核心机制:
ReadView 是事务在执行 SELECT 时生成的一致性快照。包含四个核心字段:
// 源码位置: storage/innobase/read/read0read.cc
struct ReadView {
trx_id_t m_low_limit_id; // 当前最大事务ID + 1(大于等于此ID的事务不可见)
trx_id_t m_up_limit_id; // 最小活跃事务ID(小于此ID的事务已提交,可见)
trx_id_t m_creator_trx_id; // 创建ReadView的事务ID
ids_t m_ids; // 创建ReadView时活跃事务ID列表
};
可见性判断规则:
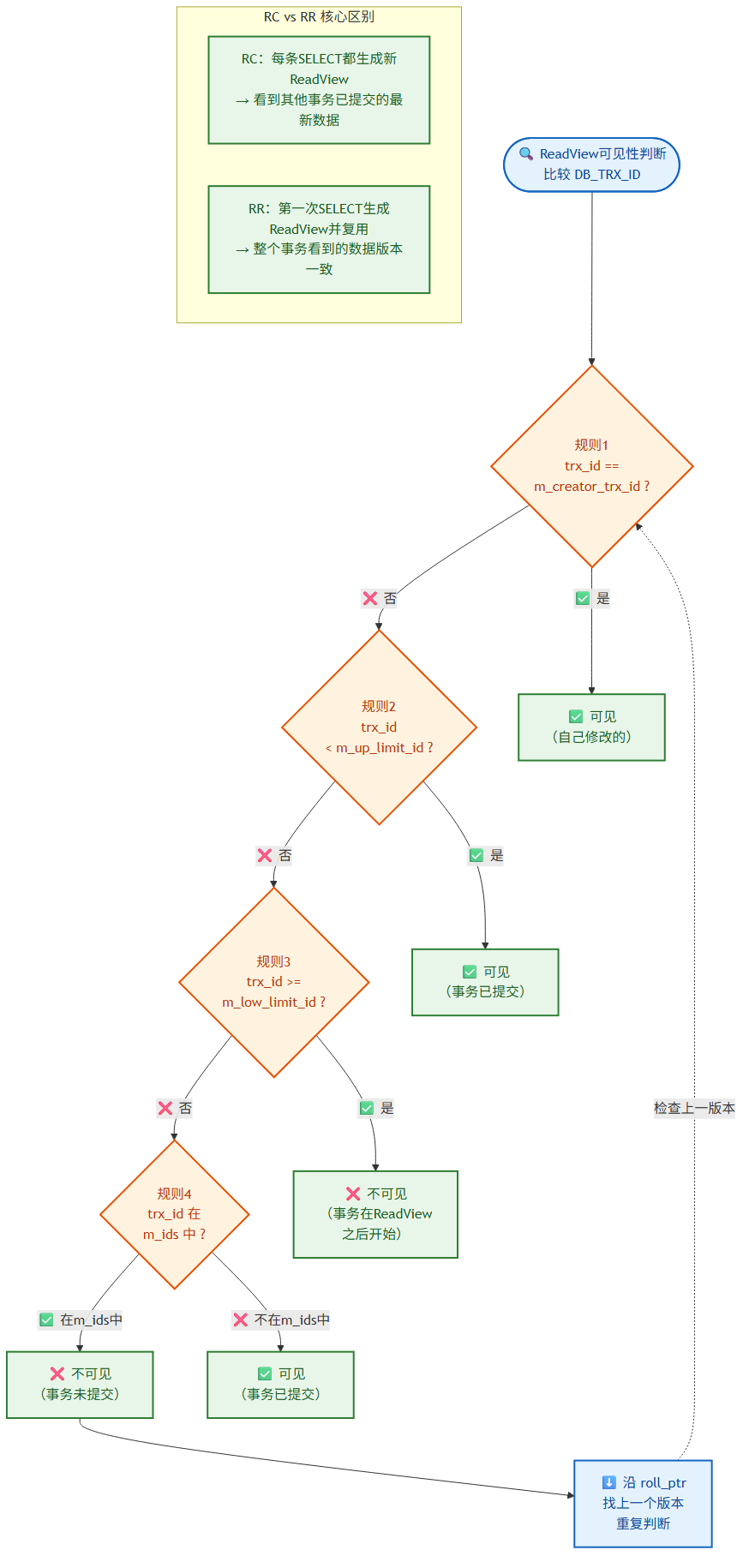
对于版本链上某一行的 DB_TRX_ID:
1. trx_id == m_creator_trx_id → 可见(自己修改的)
2. trx_id < m_up_limit_id → 可见(事务已提交)
3. trx_id >= m_low_limit_id → 不可见(事务在ReadView之后开始)
4. m_up_limit_id <= trx_id < m_low_limit_id:
- trx_id 在 m_ids 中 → 不可见(事务在活跃列表中,未提交)
- trx_id 不在 m_ids 中 → 可见(事务已提交)
5. 不可见 → 沿 roll_ptr 找上一个版本,重复判断
RC vs RR 的核心区别——ReadView 生成时机:
- RC(READ COMMITTED):每条 SELECT 语句都生成新的 ReadView。所以能看到其他事务已提交的最新数据,导致不可重复读。
- RR(REPEATABLE READ):事务中第一次 SELECT 时生成 ReadView,后续复用。所以整个事务期间看到的数据版本一致。
这是面试中最核心的 MVCC 知识点。
4.4 快照读 vs 当前读
| 读类型 | 说明 | 是否使用MVCC | 示例 |
|---|---|---|---|
| 快照读 | 读取ReadView对应的历史版本 | ✅ | 普通 SELECT |
| 当前读 | 读取最新已提交版本,加锁 | ❌ | SELECT … LOCK IN SHARE MODE / SELECT … FOR UPDATE / UPDATE / DELETE / INSERT |
-- 快照读(MVCC)
SELECT * FROM users WHERE id = 1;
-- 当前读(加锁,读最新版本)
SELECT * FROM users WHERE id = 1 FOR UPDATE; -- 加X锁
SELECT * FROM users WHERE id = 1 LOCK IN SHARE MODE; -- 加S锁
UPDATE users SET name = '李四' WHERE id = 1; -- 加X锁
五、InnoDB 锁机制全解
5.1 锁的分类体系
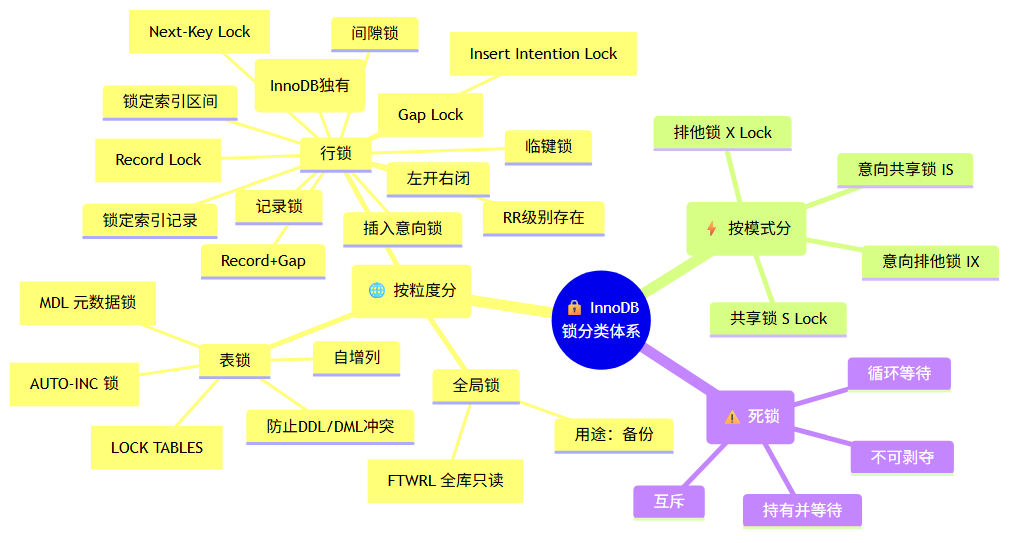
按粒度分:
├── 全局锁(FTWRL)——全库只读,用于备份
├── 表锁
│ ├── 表锁(LOCK TABLES)
│ ├── 元数据锁(MDL)——防止DDL/DML冲突
│ └── AUTO-INC 锁——自增列
└── 行锁(InnoDB独有)
├── Record Lock(记录锁)——锁定索引记录
├── Gap Lock(间隙锁)——锁定索引区间,不含记录本身
└── Next-Key Lock(临键锁)——Record + Gap,左开右闭
5.2 行锁详解
Record Lock(记录锁):
锁定索引上的一条记录。只有通过索引检索数据时才使用行锁,否则退化为表锁。
-- 假设id是主键
SELECT * FROM t WHERE id = 1 FOR UPDATE;
-- 仅锁定 id=1 这条记录
Gap Lock(间隙锁):
锁定索引记录之间的间隙,防止其他事务在间隙中插入数据。仅在 RR 隔离级别下存在。
-- 表中存在 id=10, id=20, id=30
SELECT * FROM t WHERE id BETWEEN 15 AND 25 FOR UPDATE;
-- Gap Lock 锁定 (10,20) 和 (20,30) 之间的间隙
-- 其他事务无法插入 id=11~19, 21~29 的记录
Next-Key Lock(临键锁):
Record Lock + Gap Lock 的组合,左开右闭区间 (10, 20]。这是 InnoDB 行锁的默认加锁方式。
Insert Intention Lock(插入意向锁):
一种特殊的间隙锁,表示事务意图在间隙中插入数据。多个事务可以在同一间隙持有插入意向锁(不互相阻塞),但与间隙锁冲突。
5.3 加锁规则分析(面试重点)
以下分析基于 RR 隔离级别,InnoDB 引擎:
场景一:主键等值查询
-- 表数据: id=10, 20, 30
-- 记录存在
SELECT * FROM t WHERE id = 10 FOR UPDATE;
-- 加锁: id=10 的 Record Lock
-- 记录不存在
SELECT * FROM t WHERE id = 15 FOR UPDATE;
-- 加锁: (10, 20) 的 Gap Lock
场景二:主键范围查询
SELECT * FROM t WHERE id >= 10 AND id < 20 FOR UPDATE;
-- 加锁: [10] 的 Record Lock + (10, 20) 的 Gap Lock
-- 即 Next-Key Lock (−∞, 10] + (10, 20)
场景三:唯一索引等值查询
-- 唯一索引 uk_col, 存在值 'A', 'C'
SELECT * FROM t WHERE uk_col = 'B' FOR UPDATE;
-- 记录不存在: ('A', 'C') 的 Gap Lock
场景四:非唯一索引等值查询
-- 非唯一索引 idx_col, 存在值 5, 10, 10, 15
SELECT * FROM t WHERE idx_col = 10 FOR UPDATE;
-- 加锁: (5, 10], (10, 15) 的 Next-Key Lock
-- 注意: 非唯一索引会向右扫描到第一个不满足条件的值
场景五:无索引查询
SELECT * FROM t WHERE col = 1 FOR UPDATE;
-- col 无索引 → 全表扫描,每行都加 Next-Key Lock
-- 效果等同于锁表!
结论:行锁是加在索引上的。如果没有索引,扫描所有行都加锁,效果等同于表锁。
5.4 死锁分析与排查
死锁产生的四个必要条件:互斥、持有并等待、不可剥夺、循环等待。
InnoDB 死锁检测:innodb_deadlock_detect(默认 ON),检测到死锁后回滚代价较小的事务。
-- 查看最近一次死锁信息
SHOW ENGINE INNODB STATUS\G
-- 搜索 "LATEST DETECTED DEADLOCK" 段
-- 开启全部死锁日志
SET GLOBAL innodb_print_all_deadlocks = ON;
-- 之后在 MySQL 错误日志中查看
-- 查看当前锁等待
SELECT * FROM performance_schema.data_locks;
SELECT * FROM performance_schema.data_lock_waits;
死锁排查工具链:
-- 1. 查看正在运行的事务
SELECT * FROM information_schema.innodb_trx;
-- 2. 查看锁等待关系
SELECT
r.trx_id AS waiting_trx_id,
r.trx_mysql_thread_id AS waiting_thread,
r.trx_query AS waiting_query,
b.trx_id AS blocking_trx_id,
b.trx_mysql_thread_id AS blocking_thread,
b.trx_query AS blocking_query
FROM performance_schema.data_lock_waits w
JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_engine_transaction_id
JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_engine_transaction_id;
-- 3. 杀掉阻塞进程
KILL <thread_id>;
常见死锁场景与规避:
- 交叉更新:事务A先更新表1再更新表2,事务B相反 → 统一加锁顺序
- 间隙锁冲突:两个事务都在同一间隙持有 Gap Lock 并尝试插入 → 缩小事务范围
- 唯一索引冲突重试:INSERT 唯一键冲突后持有 S 锁,并发场景死锁 → 使用 INSERT … ON DUPLICATE KEY UPDATE
六、日志系统深度解析
6.1 三大日志对比
| 日志 | 层级 | 作用 | 写入时机 | 内容 |
|---|---|---|---|---|
| Redo Log | InnoDB 引擎层 | 崩溃恢复(持久性) | 事务执行中持续写入 | 物理日志:页号+偏移+修改内容 |
| Undo Log | InnoDB 引擎层 | 事务回滚 + MVCC | 修改前先写Undo | 逻辑日志:修改前的旧值 |
| Binlog | Server 层 | 主从复制 + 数据恢复 | 事务提交时写入 | 逻辑日志:SQL语句或行变更 |
6.2 Redo Log 深度机制
WAL(Write-Ahead Logging)机制:
先写日志,后写数据。修改数据时:① 先修改 Buffer Pool 中的数据页(变为脏页)→ ② 先写 Redo Log Buffer → ③ 写 Redo Log 文件 → ④ 后台异步将脏页刷盘。
这样做的好处:将随机写转化为顺序写,大幅提升性能。
Redo Log 结构:

ib_logfile0 / ib_logfile1 (循环写入)
├── 固定大小,如 1GB × 2个文件
├── head(write pos)—— 当前写入位置,不断推进
└── tail(checkpoint)—— 恢复起点,追赶 write pos
└── write pos - checkpoint 之间是未刷盘的脏页对应的redo
LSN(Log Sequence Number):
LSN 是一个单调递增的整数,标记日志和页的版本。
| LSN 类型 | 含义 |
|---|---|
log sequence number |
Redo Log Buffer 中最新的 LSN |
log flushed up to |
已刷入磁盘的 Redo Log LSN |
pages flushed up to |
Buffer Pool 中最老的脏页 LSN |
last checkpoint at |
最新 checkpoint 的 LSN |
SHOW ENGINE INNODB STATUS\G
-- 搜索 "LOG" 段查看 LSN
Checkpoint 机制:
- Sharp Checkpoint:将所有脏页刷盘(仅在关闭时使用)。
- Fuzzy Checkpoint:InnoDB 运行时使用,分批刷脏页。触发条件:
- Redo Log 快满(
write pos追上checkpoint) - Buffer Pool 脏页比例超过阈值(
innodb_max_dirty_pages_pct,默认 90%) - Master Thread 周期性刷新
- 闲置时刷新
- Redo Log 快满(
6.3 Undo Log 机制
Undo Log 存储修改前的数据版本,用于:
- 事务回滚(原子性)
- MVCC 历史版本链
-- MySQL 8.0 Undo 独立表空间
SHOW VARIABLES LIKE 'innodb_undo_tablespaces'; -- 默认2个
SHOW VARIABLES LIKE 'innodb_undo_log_truncate'; -- 自动截断,默认ON
Undo Log 类型:
- insert undo log:INSERT 产生的 undo,事务提交后即可删除(不需要 MVCC)。
- update undo log:UPDATE/DELETE 产生的 undo,需要保留供 MVCC 使用。由 Purge Thread 在无活跃事务引用时回收。
长时间运行的大事务会导致 Undo Log 膨胀,引发 undo log 表空间增长、历史版本链过长、查询变慢。生产中务必避免长事务。
6.4 Binlog 机制
Binlog 格式:
| 格式 | 内容 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|---|
| STATEMENT | SQL 原文 | 日志量小 | 函数/UUID等不确定结果导致主从不一致 | 简单场景 |
| ROW | 行变更(前像+后像) | 精确,主从一致 | 日志量大(尤其批量操作) | 生产推荐 |
| MIXED | 自动选择 | 折中 | 复杂度高 | 兼容场景 |
SHOW VARIABLES LIKE 'binlog_format'; -- 生产推荐 ROW
SHOW VARIABLES LIKE 'binlog_row_image'; -- MINIMAL(仅变更列) / FULL(全部列)
两阶段提交(2PC)——保证 Redo Log 和 Binlog 一致性:
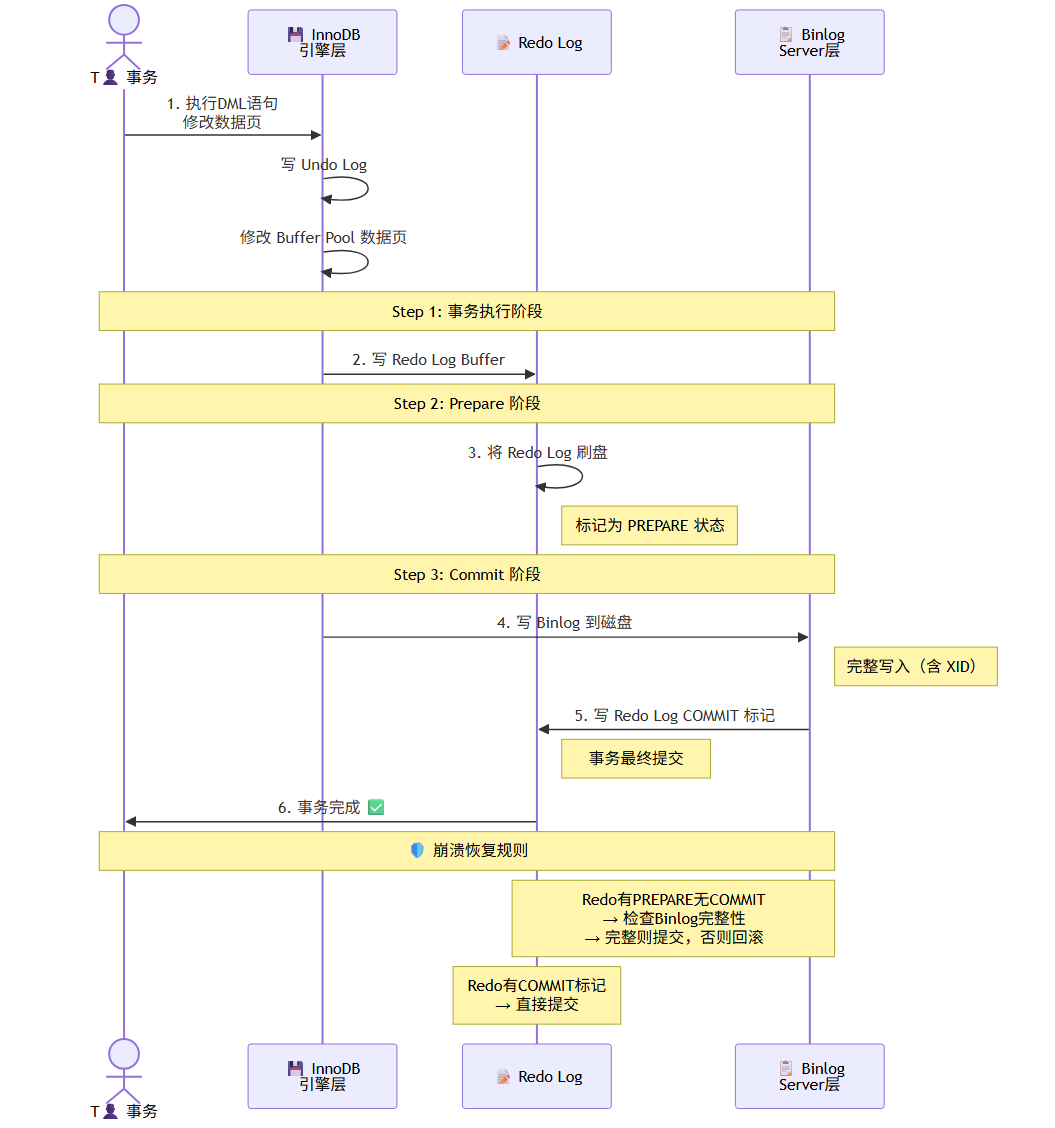
1. InnoDB 事务执行 → 写 Undo Log → 修改数据页 → 写 Redo Log Buffer
2. 【Prepare阶段】写 Redo Log 到磁盘(标记为 PREPARE 状态)
3. 【Commit阶段】写 Binlog 到磁盘 → 写 Redo Log 的 COMMIT 标记
4. 事务完成
崩溃恢复规则:
- 如果 Redo Log 有 PREPARE 标记但无 COMMIT 标记:
- 检查 Binlog 是否完整(有无 XID)→ 完整则提交,不完整则回滚
- 如果 Redo Log 有 COMMIT 标记 → 直接提交
这保证了 Redo Log 和 Binlog 的原子性,即使崩溃也不会出现主从数据不一致。
-- sync_binlog 参数
SHOW VARIABLES LIKE 'sync_binlog';
-- 0: 依赖OS刷盘(性能好,可能丢日志)
-- 1: 每次提交都fsync(默认,最安全)
-- N: 每N次提交fsync(折中)
生产推荐:innodb_flush_log_at_trx_commit=1 + sync_binlog=1(双1配置)。
七、SQL 执行计划与优化
7.1 EXPLAIN 执行计划详解
EXPLAIN SELECT * FROM users WHERE name = '张三' AND age > 25;
| 列 | 说明 | 关注点 |
|---|---|---|
| id | 查询序号 | id相同从上往下执行;id不同,大的先执行 |
| select_type | 查询类型 | SIMPLE/PRIMARY/SUBQUERY/DERIVED/UNION |
| table | 表名 | |
| type | 访问类型 | 核心指标,从好到差见下表 |
| possible_keys | 可能用到的索引 | |
| key | 实际使用的索引 | NULL表示未走索引 |
| key_len | 索引使用长度 | 判断联合索引用了几个列 |
| ref | 索引比较来源 | const/列名/func |
| rows | 估算扫描行数 | 越小越好 |
| filtered | 过滤后比例 | 百分比,越接近100%越好 |
| Extra | 额外信息 | 关键优化线索 |
type 访问类型(从好到差):
system > const > eq_ref > ref > range > index > ALL
| | | | | | |
表只有 主键/唯一 JOIN时使用 非唯一索引 范围 全索引 全表
一行 索引等值 唯一索引 等值匹配 扫描 扫描 扫描
查询
Extra 常见值:
| 值 | 含义 | 优化建议 |
|---|---|---|
| Using index | 覆盖索引 | ✅ 最好 |
| Using where | Server层过滤 | 检查是否可下推到索引 |
| Using index condition | 索引下推ICP | ✅ 已优化 |
| Using temporary | 使用临时表 | 需优化GROUP BY/DISTINCT |
| Using filesort | 额外排序 | 检查ORDER BY是否能用索引 |
| Using join buffer | 使用BNL连接 | 被驱动表没有索引 |
| Select tables optimized away | 优化器已处理 | ✅ 如COUNT(*)走索引 |
7.2 key_len 计算
key_len 表示索引中使用的字节数,可用于判断联合索引用了几列。
计算规则(字符集 utf8mb4 下):
| 数据类型 | key_len |
|---|---|
| CHAR(n) | n × 4 |
| VARCHAR(n) | n × 4 + 2(变长)+ 1(NULL标记) |
| INT | 4 |
| BIGINT | 8 |
| DATE | 3 |
| DATETIME | 5 |
| TIMESTAMP | 4 |
-- 联合索引 (name VARCHAR(20), age INT)
EXPLAIN SELECT * FROM t WHERE name = '张三' AND age > 25;
-- key_len = 20*4 + 2 + 1 + 4 = 87 → name和age都用了索引
EXPLAIN SELECT * FROM t WHERE name = '张三';
-- key_len = 20*4 + 2 + 1 = 83 → 只用了name
7.3 JOIN 原理与优化
Nested Loop Join(嵌套循环连接):
最基础的 JOIN 算法。对驱动表的每一行,遍历被驱动表查找匹配。
for (row in 驱动表) {
for (row2 in 被驱动表) {
if (match) output(row, row2)
}
}
Block Nested Loop Join(BNL)——无索引时使用:
将驱动表数据放入 join_buffer,然后批量扫描被驱动表,减少被驱动表的扫描次数。
Index Nested Loop Join(NLJ)——被驱动表有索引时使用:
驱动表的每行通过被驱动表的索引快速定位,效率高。
Hash Join(MySQL 8.0.18+)——替代 BNL:
在内存中构建驱动表的 Hash 表,然后扫描被驱动表进行 Hash 匹配。时间复杂度 O(n+m),远优于 BNL 的 O(n×m)。
-- MySQL 8.0 查看是否使用 Hash Join
EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.id = t2.t_id;
-- 输出 "<Hash join>"
JOIN 优化原则:
- 小表驱动大表(MySQL 优化器自动选择,但有时需要 STRAIGHT_JOIN 强制顺序)
- 被驱动表的 JOIN 列建索引
- ON 条件列类型必须一致(否则无法使用索引)
- 减少 JOIN 的表数量(阿里规范不超过3张表)
7.4 慢查询优化实战
-- 1. 开启慢查询日志
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1; -- 超过1秒记录
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
-- 2. 分析慢查询日志
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# -s t 按时间排序 -t 10 取前10条
-- 3. pt-query-digest 更详细分析
pt-query-digest /var/log/mysql/slow.log
-- 4. EXPLAIN 分析
EXPLAIN SELECT ...
-- 5. 查看实际执行成本
SET optimizer_trace='enabled=on';
SELECT ...;
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
常见慢查询优化思路:
- 全表扫描 → 加索引
- 索引失效 → 检查函数/类型转换/最左前缀
- 文件排序 → 优化 ORDER BY 使用索引
- 临时表 → 优化 GROUP BY
- 大分页 → 游标分页
WHERE id > last_id LIMIT 10 - COUNT 慢 → 维护计数表或使用 Redis 缓存
- 深分页
LIMIT 1000000, 10→ 延迟关联或子查询优化
-- 深分页优化:延迟关联
SELECT t.* FROM users t
INNER JOIN (SELECT id FROM users ORDER BY create_time LIMIT 1000000, 10) tmp
ON t.id = tmp.id;
八、主从复制与高可用
8.1 主从复制原理
三个线程协作:
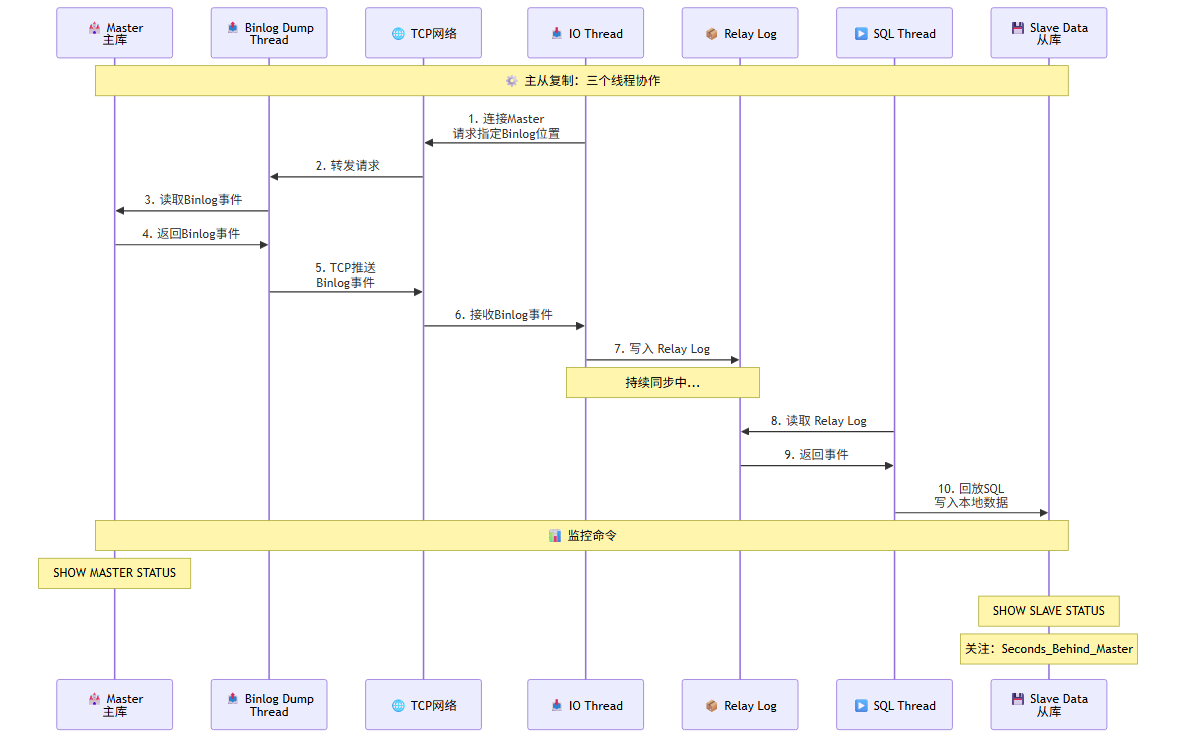
Master Slave
┌──────────────┐ ┌──────────────────┐
│ Binlog Dump │ TCP推送 │ IO Thread │
│ Thread │──────────────→│ 读取Binlog │
│ (读取Binlog) │ Binlog事件 │ 写入Relay Log │
└──────────────┘ └──────────────────┘
│
↓
┌──────────────────┐
│ SQL Thread │
│ 回放Relay Log │
│ 写入本地数据 │
└──────────────────┘
复制流程:
- Slave 的 IO Thread 连接 Master,请求从指定 Binlog 位置开始的数据。
- Master 的 Binlog Dump Thread 读取 Binlog,发送给 Slave。
- Slave 的 IO Thread 将收到的事件写入 Relay Log。
- Slave 的 SQL Thread 读取 Relay Log,回放 SQL,更新数据。
-- 主库
SHOW MASTER STATUS; -- 查看当前Binlog位置
SHOW BINLOG EVENTS IN 'mysql-bin.000001' LIMIT 10;
-- 从库
SHOW SLAVE STATUS\G -- 8.0: SHOW REPLICA STATUS\G
-- 关注: Slave_IO_Running / Slave_SQL_Running / Seconds_Behind_Master
8.2 复制方式
| 复制方式 | 原理 | 优缺点 |
|---|---|---|
| 异步复制 | 主库写完Binlog即返回,不等从库 | 性能最好,可能丢数据 |
| 半同步复制 | 主库至少等待一个从库收到Binlog | 性能与数据安全的折中 |
| 全同步复制 | 主库等待所有从库执行完毕 | 性能最差,几乎不用 |
| 组复制(MGR) | 基于Paxos变体协议 | 自动选主,强一致性 |
-- 半同步复制配置
-- 主库
INSTALL PLUGIN rpl_semi_sync_source SONAME 'semisync_source.so';
SET GLOBAL rpl_semi_sync_source_enabled = 1;
SET GLOBAL rpl_semi_sync_source_timeout = 1000; -- 1秒超时降级
-- 从库
INSTALL PLUGIN rpl_semi_sync_replica SONAME 'semisync_replica.so';
SET GLOBAL rpl_semi_sync_replica_enabled = 1;
8.3 GTID 复制
GTID(Global Transaction Identifier)= server_uuid:transaction_id,全局唯一标识每个事务。
优势:自动定位复制位置,避免传统基于位点复制的复杂性;主从切换更简单。
-- 开启GTID
gtid_mode = ON
enforce_gtid_consistency = ON
-- 建立复制
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='192.168.1.100',
SOURCE_PORT=3306,
SOURCE_USER='repl',
SOURCE_PASSWORD='xxx',
SOURCE_AUTO_POSITION=1; -- GTID自动定位
8.4 读写分离与分库分表
读写分离架构:
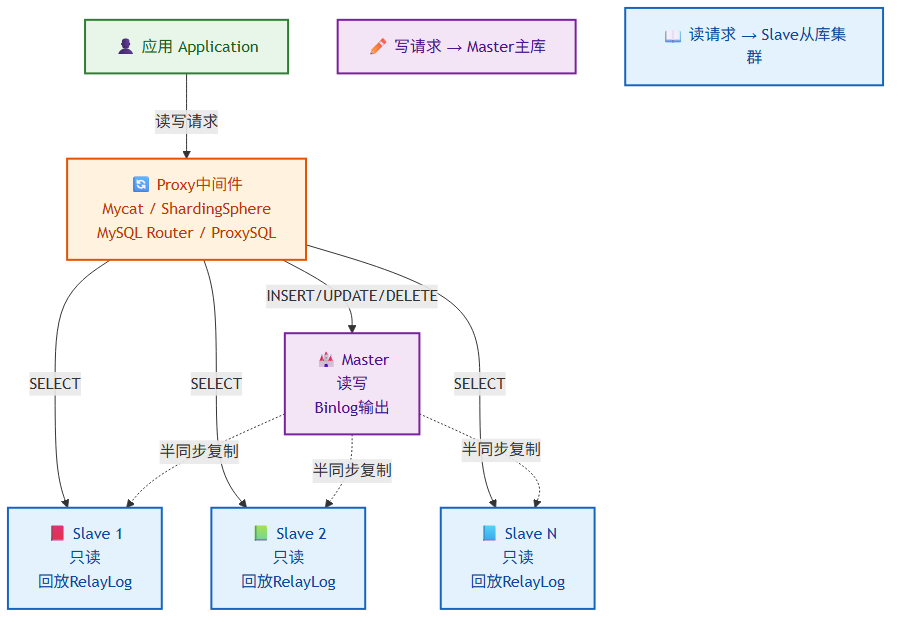
应用 → Proxy(Mycat/ShardingSphere/MySQL Router/ProxySQL)
├── 写请求 → Master
└── 读请求 → Slave1/Slave2/...
主从延迟问题:
原因:从库单线程回放(MySQL 5.7开始支持并行复制,基于组提交或 WRITESET)。
解决方案:
- 关键场景强制读主库
- 半同步复制减少延迟窗口
- MySQL 8.0 并行复制(基于 WRITESET 的依赖检测)
-- 8.0 并行复制配置
SET GLOBAL binlog_transaction_dependency_tracking = WRITESET;
SET GLOBAL slave_parallel_workers = 16;
SET GLOBAL slave_parallel_type = LOGICAL_CLOCK;
分库分表策略:
| 方式 | 场景 | 方案 |
|---|---|---|
| 垂直分库 | 按业务拆分 | 用户库、订单库、商品库 |
| 垂直分表 | 大字段拆分 | 主表+扩展表 |
| 水平分表 | 单表数据量大 | 按范围/Hash/一致性Hash分片 |
中间件:ShardingSphere、MyCat、Vitess
分片键选择原则:高基数、均匀分布、查询带分片键、避免跨片 JOIN。
九、生产实战经验
9.1 大表 DDL 优化
传统 ALTER TABLE 在大表上会长时间锁表。
Online DDL(MySQL 5.6+):
-- 查看DDL是否支持在线
ALTER TABLE users ADD COLUMN email VARCHAR(255), ALGORITHM=INPLACE, LOCK=NONE;
-- ALGORITHM=INPLACE: 不复制全表(尽量)
-- ALGORITHM=COPY: 复制全表(最慢,锁表)
-- LOCK=NONE: 不锁表(允许DML)
-- LOCK=SHARED: 允许读不允许写
pt-online-schema-change(pt-osc):
原理:创建影子表 → 在原表上建触发器 → 分批拷贝数据 → 重命名表。
pt-online-schema-change \
--alter "ADD COLUMN email VARCHAR(255)" \
--execute \
D=mydb,t=users,h=127.0.0.1,u=root,p=xxx
gh-ost(GitHub 出品):
不使用触发器,通过 Binlog 解析实现数据同步,对主库压力更小。
9.2 连接池配置
# 最大连接数
max_connections = 2000
# 交互超时(8小时太长,建议缩短)
wait_timeout = 600
interactive_timeout = 600
# 连接排队
back_log = 500
# 查看连接使用
SHOW STATUS LIKE 'Threads_%';
SHOW STATUS LIKE 'Max_used_connections';
SHOW STATUS LIKE 'Aborted_%';
应用侧连接池(HikariCP/Druid)配置:
maxPoolSize:CPU核心数 × 2 + 磁盘数(经验公式),一般 10-20minIdle:与 maxPoolSize 相同(HikariCP 推荐)maxLifetime:30分钟以内(比 MySQLwait_timeout短)connectionTimeout:30秒idleTimeout:10分钟
9.3 核心参数调优清单
# ===== InnoDB 内存 =====
innodb_buffer_pool_size = 物理内存的60-80%
innodb_buffer_pool_instances = 8 # 大Buffer Pool时增加
# ===== Redo Log =====
innodb_log_file_size = 1G # 大Redo Log提升性能
innodb_log_files_in_group = 2
innodb_flush_log_at_trx_commit = 1 # 双1
# ===== Binlog =====
log_bin = mysql-bin
binlog_format = ROW
binlog_row_image = MINIMAL
sync_binlog = 1 # 双1
# ===== 并发 =====
innodb_read_io_threads = 8
innodb_write_io_threads = 8
innodb_purge_threads = 4
# ===== 脏页刷盘 =====
innodb_max_dirty_pages_pct = 75 # 生产建议调低
innodb_max_dirty_pages_pct_lwm = 10 # 低水位线
# ===== 临时表 =====
tmp_table_size = 256M
max_heap_table_size = 256M
# ===== 排序 =====
sort_buffer_size = 4M # 每个连接,不要设太大
join_buffer_size = 4M
9.4 监控关键指标
| 指标 | 命令 | 告警阈值 |
|---|---|---|
| 活跃连接数 | SHOW STATUS LIKE 'Threads_connected' |
> max_connections × 80% |
| 慢查询数 | SHOW STATUS LIKE 'Slow_queries' |
每分钟增长 > 10 |
| Buffer Pool 命中率 | SHOW STATUS LIKE 'Innodb_buffer_pool_read%' |
< 99% |
| 脏页比例 | SHOW STATUS LIKE 'Innodb_buffer_pool_pages_dirty' |
> 80% |
| 主从延迟 | SHOW SLAVE STATUS → Seconds_Behind_Master |
> 60s |
| 死锁次数 | SHOW STATUS LIKE 'Innodb_deadlocks' |
每小时 > 5 |
| Undo 表空间大小 | information_schema.innodb_sys_tablespaces |
持续增长 |
9.5 备份与恢复
# 逻辑备份
mysqldump --single-transaction --master-data=2 --routines --triggers \
--all-databases > backup.sql
# 物理备份(Percona XtraBackup)
xtrabackup --backup --target-dir=/backup/full
xtrabackup --prepare --target-dir=/backup/full
xtrabackup --copy-back --target-dir=/backup/full
# 增量备份
xtrabackup --backup --target-dir=/backup/inc1 \
--incremental-basedir=/backup/full
# Binlog 恢复到指定时间点
mysqlbinlog --start-datetime="2024-06-01 12:00:00" \
--stop-datetime="2024-06-01 13:00:00" \
mysql-bin.000123 | mysql -u root -p
# 基于 GTID 恢复
mysqlbinlog --skip-gtids=true \
--include-gtids='uuid:1-100' \
mysql-bin.000123 | mysql -u root -p
9.6 常见故障排查
CPU 飙高:
-- 1. 查看活跃会话
SHOW PROCESSLIST;
-- 2. 查看正在执行的事务
SELECT * FROM information_schema.innodb_trx;
-- 3. 查看锁等待
SELECT * FROM performance_schema.data_lock_waits;
-- 4. 查看正在执行的SQL
SELECT * FROM performance_schema.events_statements_current;
磁盘空间满:
-- 查看各表空间大小
SELECT
table_schema AS '数据库',
SUM(data_length + index_length) / 1024 / 1024 AS 'MB'
FROM information_schema.tables
GROUP BY table_schema
ORDER BY MB DESC;
-- 清理大表
-- 不要用 DELETE,用 TRUNCATE(释放空间)
TRUNCATE TABLE large_log_table;
-- Binlog 占用空间
SHOW VARIABLES LIKE 'binlog_expire_logs_seconds'; -- 默认30天
PURGE BINARY LOGS BEFORE '2024-06-01 00:00:00';
十、分层面试题
初级篇
Q1:MySQL 一条 UPDATE 语句的执行流程?
答:① 解析器生成解析树 → ② 优化器选择执行计划 → ③ 执行器调用 InnoDB 接口 → ④ 加 X 锁(当前读)→ ⑤ 写 Undo Log(记录旧值)→ ⑥ 修改 Buffer Pool 中的数据页 → ⑦ 写 Redo Log Buffer → ⑧ 事务提交时写 Redo Log(PREPARE)→ ⑨ 写 Binlog → ⑩ 写 Redo Log(COMMIT)→ ⑪ 释放锁。
Q2:varchar(50) 中的 50 是什么意思?
答:50 表示字符数(不是字节数),与字符集无关。在 utf8mb4 下,一个字符最多 4 字节,所以 varchar(50) 最多占 200 字节。另外 varchar 需要 1-2 字节记录长度(长度 ≤255 用 1 字节,否则 2 字节)。
Q3:char 和 varchar 的区别?
答:char 是定长,不足补空格;varchar 是变长,按实际存储。char 适合固定长度数据(如 MD5 哈希值、手机号),varchar 适合变长数据。char 的检索效率略高(不需要计算偏移),但浪费空间。
Q4:NULL 值有什么问题?
答:① NULL 占用额外空间(bitmap 中标记);② NULL 不等于 NULL(NULL = NULL 结果为 NULL);③ 不利于索引优化(NULL 值在索引中的处理复杂);④ 聚合函数忽略 NULL。建议用 NOT NULL DEFAULT ‘’ 或 0 替代。
中级篇
Q5:MySQL 为什么选择 B+树而不是 B树或 Hash 索引?
答:B+树相比 B树——① 非叶子节点不存数据,每个节点能存更多键值,树更矮,IO 更少;② 叶子节点通过双向链表连接,范围查询高效;③ 所有数据都在叶子节点,查询性能稳定。
Hash 索引——① 不支持范围查询(>, <, BETWEEN);② 不支持排序;③ 不支持最左前缀匹配;④ 等值查询 O(1) 确实快但不通用。Memory 引擎默认使用 Hash 索引。
Q6:聚簇索引和非聚簇索引的区别?
答:聚簇索引将数据和索引存在同一个 B+树中,叶子节点直接存储行数据,一张表只能有一个。非聚簇索引(二级索引)的叶子节点存储主键值,需要回表才能获取完整行数据。InnoDB 主键索引是聚簇索引,MyISAM 索引和数据分离(都是非聚簇索引,堆表结构)。
Q7:什么是最左前缀原则?为什么会有这个原则?
答:联合索引 (a, b, c) 在 B+树中按照 a→b→c 的顺序排列。如果查询不包含 a,就无法利用 B+树的有序性来定位数据,只能全索引扫描。只有从最左列开始连续匹配,才能逐层缩小搜索范围。范围查询(>, <, LIKE 'x%')之后的列无法使用索引,因为范围查询后的数据不再保证有序。
Q8:MySQL 的 MVCC 是怎么实现的?
答:MVCC 通过三个组件实现:① 每行数据的隐藏列 DB_TRX_ID(修改事务ID)和 DB_ROLL_PTR(指向Undo Log);② Undo Log 形成的版本链;③ ReadView 读视图。事务执行 SELECT 时生成 ReadView,通过比较行的 DB_TRX_ID 与 ReadView 中的活跃事务列表,判断当前版本是否可见,不可见则沿版本链查找历史版本。RC 隔离级别每次 SELECT 都生成新 ReadView,RR 隔离级别复用第一次的 ReadView。
高级篇
Q9:InnoDB 中一条 DELETE 语句的加锁过程?
答:DELETE 语句是当前读,会对匹配的行加 X 锁。在 RR 隔离级别下:
- 如果通过唯一索引等值删除且记录存在:加 Record Lock。
- 如果通过非唯一索引等值删除:加 Next-Key Lock,并向右扫描到第一个不满足条件的记录,该记录加 Gap Lock。
- 如果通过范围条件删除:对范围内的每条记录加 Next-Key Lock。
- 如果通过无索引列删除:全表每行加 Next-Key Lock,效果等同于锁表。
Q10:Redo Log 和 Binlog 有什么区别?为什么要两阶段提交?
答:Redo Log 是 InnoDB 引擎层的物理日志(记录页的物理修改),用于崩溃恢复。Binlog 是 Server 层的逻辑日志(记录 SQL 或行变更),用于主从复制和数据恢复。
两阶段提交保证两者的一致性:先写 Redo Log(PREPARE),再写 Binlog,最后写 Redo Log(COMMIT)。如果崩溃在 PREPARE 后、Binlog 前:回滚(Binlog 没写,从库不会有这条数据)。如果崩溃在 Binlog 后、COMMIT 前:检查 Binlog 完整性,完整则提交(保证主从一致),不完整则回滚。
Q11:如何排查和解决 MySQL 主从延迟问题?
答:延迟原因——从库单线程回放慢于主库写入。
排查:SHOW SLAVE STATUS\G 查看 Seconds_Behind_Master;查看从库 CPU/IO/网络;查看 Slave_SQL_Running 状态。
解决方案:① MySQL 5.7+ 开启并行复制(slave_parallel_workers);② MySQL 8.0 使用 WRITESET 依赖检测提升并行度;③ 大事务拆分;④ 从库使用更好的硬件;⑤ 关键读操作走主库;⑥ 使用半同步复制减少数据丢失风险。
Q12:什么情况下会出现间隙锁?如何避免?
答:间隙锁在 RR 隔离级别下出现,用于防止幻读。当使用范围查询(>, <, BETWEEN)或等值查询记录不存在时触发。
避免方式:① 将隔离级别降为 RC(但会有幻读问题);② 使用唯一索引等值查询(命中记录时退化为 Record Lock);③ 缩小事务范围;④ 尽量使用等值查询而非范围查询。
资深/系统设计篇
Q13:设计一个支持千万级并发的 MySQL 高可用架构。
答:分层架构设计:
接入层:MySQL Router / ProxySQL 做读写分离和负载均衡。主库集群采用 MGR(MySQL Group Replication)实现自动故障转移,3节点仲裁模式。
数据层:按业务垂直分库(用户库、订单库、商品库);单库数据量大时水平分表(如按用户ID取模分16表)。使用 ShardingSphere 管理分片。
缓存层:Redis 缓存热点数据,减少数据库压力。本地缓存(Caffeine)应对超高频读。
复制层:主从半同步复制 + MySQL 8.0 并行复制(WRITESET 模式)。从库数量根据读量扩展。
容灾层:同城双活(两个机房各一套集群,DTS 实时同步);异地灾备(异步复制到异地)。
监控层:Prometheus + Grafana 监控数据库指标;ELK 收集慢查询日志;自动告警。
关键参数:innodb_buffer_pool_size 占物理内存 70%;sync_binlog=1 + innodb_flush_log_at_trx_commit=1(双1);连接池 HikariCP 限制连接数。
Q14:如何实现 MySQL 的幂等性插入?
答:三种方案:
方案一:唯一索引 + INSERT IGNORE。建唯一索引,插入冲突时自动忽略。适合简单的幂等场景。
方案二:唯一索引 + INSERT … ON DUPLICATE KEY UPDATE。冲突时更新指定字段。适合 upsert 场景。
方案三:分布式锁 + 查询判断。先获取 Redis 分布式锁,查询是否存在,不存在再插入。适合复杂业务逻辑。
-- 方案一
INSERT IGNORE INTO orders (order_no, user_id, amount) VALUES ('ORD001', 1, 100);
-- 方案二
INSERT INTO orders (order_no, user_id, amount, update_time)
VALUES ('ORD001', 1, 100, NOW())
ON DUPLICATE KEY UPDATE amount = VALUES(amount), update_time = NOW();
注意:方案二在高并发下可能有死锁风险(多个事务同时持有 S 锁再请求 X 锁),需要捕获死锁异常并重试。
Q15:MySQL 中 COUNT(*) / COUNT(1) / COUNT(列) 的区别?哪个最快?
答:COUNT(*) 和 COUNT(1) 在 InnoDB 中没有本质区别,优化器会选择最小的索引扫描(MySQL 5.7+ 对 COUNT(*) 有专门优化)。COUNT(列) 会忽略 NULL 值,且不会优化为索引扫描(如果该列没有索引的话)。
性能:COUNT(*) ≈ COUNT(1) > COUNT(主键列) > COUNT(普通列)。
大表 COUNT 慢的解决方案:① 维护计数表(实时更新);② Redis 缓存近似值;③ SHOW TABLE STATUS 获取估算值(不精确);④ 信息_schema 的 table_rows(估算值)。
Q16:如何做 MySQL 数据迁移不停机?
答:双写迁移方案:
阶段一:全量同步。使用 gh-ost 或 XtraBackup 将全量数据同步到新库。
阶段二:增量同步。通过 Binlog 解析(Canal/Debezium)将增量变更实时同步到新库。
阶段三:双写灰度。应用层同时写新老两个库,读仍走老库。设置开关控制比例(1%→10%→50%→100%)。
阶段四:读流量切换。灰度将读流量从老库切到新库,对比数据一致性。
阶段五:停写老库。确认新库稳定后,停止双写,仅写新库。
阶段六:清理。下线老库,回收资源。
关键点:每一步都要有回滚方案,灰度切换要可逆,数据一致性校验要自动化。
Q17:什么情况下索引反而会降低性能?
答:① 数据量小的表,索引维护成本大于查询收益;② 写多读少的表,每次写操作都要维护索引;③ 区分度低的列(如性别),索引扫描后大量回表;④ 大量重复值的列;⑤ 频繁更新的列,索引页分裂严重;⑥ 冗余索引,多个索引前缀重复,浪费空间和写性能。
定期使用 sys.schema_unused_indexes 检查未使用的索引并清理。
Q18:MySQL 的 READ COMMITTED 隔离级别下会有什么并发问题?如何解决?
答:RC 级别下会出现不可重复读(同一事务中两次读同一行结果不同)和幻读(范围查询结果集变化)。不会出现脏读。
解决方案:① 使用 RR 隔离级别(InnoDB 默认),MVCC 保证可重复读,Next-Key Lock 解决幻读;② 使用 SELECT ... FOR UPDATE 当前读加锁;③ 使用乐观锁(版本号机制)。
大厂实践中部分场景(如金额计算)会使用 RC + 应用层乐观锁,因为 RC 并发性更好,不产生 Gap Lock,死锁概率更低。
Q19:MySQL 的自增 ID 用完了会怎样?
答:自增列的类型决定了上限。INT UNSIGNED 最大 42 亿,BIGINT UNSIGNED 最大 1844 亿亿。如果自增 ID 用完,INSERT 会报错 ERROR 1467 (HY000): Failed to read auto-increment value from storage engine。
解决方案:① 使用 BIGINT,基本不会用完;② 分库分表,每表独立自增;③ 使用 UUID 或 Snowflake 分布式 ID。
注意:InnoDB 的自增列在 8.0 前可能会"跳跃"(事务回滚后 ID 不回收),8.0 默认模式改为 INTERLEAVED,并发性能更好但 ID 更不连续。
Q20:线上 MySQL 突然变慢,如何排查?
答:分层排查:
第一层(OS):top 查看 CPU/内存;iostat -x 1 查看磁盘 IO;netstat 查看连接数;dmesg 查看系统日志。
第二层(MySQL 实例):SHOW PROCESSLIST 查看活跃会话;SHOW ENGINE INNODB STATUS 查看 InnoDB 状态;检查 Buffer Pool 命中率;检查是否有大事务、长事务。
第三层(SQL 级别):慢查询日志分析(pt-query-digest);EXPLAIN 分析执行计划;检查是否有突增的慢查询(索引是否被误删)。
第四层(架构层面):主从延迟是否增大;是否有大批量导入/导出;是否有 DDL 操作;是否有缓存穿透导致数据库压力突增。
常见原因:① 索引缺失或失效;② 大事务/长事务;③ 锁等待/死锁;④ Buffer Pool 不足;⑤ 磁盘 IO 瓶颈;⑥ 网络问题;⑦ 主从延迟导致的读写不一致。
附录:MySQL 学习路线
第一阶段:基础(1-2周)
SQL 语法、数据类型、表设计范式、基础索引概念。目标:能写复杂 SQL,理解执行计划。
第二阶段:进阶(2-3周)
InnoDB 存储引擎、索引原理、事务隔离级别、MVCC 机制、锁体系。目标:理解底层原理,能排查锁问题。
第三阶段:高级(2-3周)
日志系统(Redo/Undo/Binlog)、主从复制原理、高可用方案、分库分表。目标:能设计高可用架构。
第四阶段:生产实战(持续)
慢查询优化、参数调优、监控告警、故障排查、数据迁移。目标:具备 DBA 级别的问题解决能力。
推荐学习资源:
- 《高性能 MySQL》(第4版)——Baron Schwartz 等
- 《MySQL 技术内幕:InnoDB 存储引擎》(第2版)——姜承尧
- MySQL 8.0 官方文档(dev.mysql.com/doc/refman/8.0/en)
- GitHub:
mysql/mysql-server源码 - Percona 博客(percona.com/blog)
源码阅读路线:
sql/sql_parse.cc—— SQL 解析入口sql/sql_optimizer.cc—— 优化器sql/sql_executor.cc—— 执行器storage/innobase/btr/btr0btr.cc—— B+树操作storage/innobase/row/row0upd.cc—— 行更新storage/innobase/trx/trx0rec.cc—— 事务 Undostorage/innobase/log/log0log.cc—— Redo Logstorage/innobase/lock/lock0lock.cc—— 锁管理
评论区