

ElasticSearch 9.x 从入门到精通实战教程
版本: ElasticSearch 9.4 (2026 年最新版)
更新日期: 2026-07-05
涵盖主题: 索引优化、查询 DSL 编写、ES|QL、向量搜索、性能调优、生产级实战
第一章 ElasticSearch 9.x 新特性与架构概览
1.1 ElasticSearch 9.4 带来了什么
ElasticSearch 9.4 于 2026 年 5 月发布,是 9.x 分支的重要里程碑版本。这个版本围绕三条主线展开:将 ES|QL 打造为一等查询引擎、通过升级 DiskBBQ 算法大幅提升向量搜索吞吐、以及通过 TSDB 合成 ID 降低指标存储开销。
对于开发者而言,9.4 最值得关注的变化包括:
| 类别 | 关键特性 | 实际影响 |
|---|---|---|
| 查询引擎 | ES|QL Views、PromQL 支持、时间序列命令 | 可像查询物理索引一样查询虚拟视图 |
| 向量搜索 | DiskBBQ 算法升级,过滤查询延迟提升 3 倍以上 | 语义检索成本大幅下降 |
| 存储优化 | TSDB 合成 ID,OTLP 指标存储减少 40% | 大规模监控场景存储成本显著降低 |
| GPU 加速 | GPU 向量索引正式 GA(集成 NVIDIA cuVS) | 索引吞吐提升 12 倍,force merge 快 7 倍 |
| 量化技术 | bbq_disk 成为默认量化模式,支持 1/2/4/7 位配置 | 新索引自动获得更优的存储与查询平衡 |
| ML 推理 | TEXT_EMBEDDING 和 RERANK 正式 GA | 语义搜索管线可稳定用于生产环境 |
向量搜索的改进尤其突出。9.4 中 DiskBBQ 算法在带限制性过滤的场景下,查询延迟改善达到 3 倍以上;通过集成 NVIDIA cuVS,GPU 加速向量索引正式 GA,自管理集群可期待 12 倍的索引吞吐提升和 7 倍的 force merge 加速。同时,semantic_text 字段类型默认采用 BFLOAT16 量化与 bbq_disk 存储,无需额外映射配置即可获得优化。
1.1.1 ES|QL Views 详解
9.4 引入了 Views 功能——将一段 ES|QL 查询封装为虚拟索引,外部可以像查询物理索引一样引用它。你可以在 FROM 子句中引用视图,就像引用物理索引一样,还可以在同一个查询中混合使用视图、索引和通配符。
-- 创建视图:标准化原始日志
CREATE VIEW clean_logs AS
FROM raw-logs-*
| RENAME @timestamp AS ts, host.name AS host
| EVAL level = UPPER(log.level)
| WHERE level != "DEBUG";
-- 像查询索引一样查询视图
FROM clean_logs
| STATS count = COUNT(*) BY host
| SORT count DESC;
安全限制:当底层索引启用了文档级安全(DLS)或字段级安全(FLS)时,视图无法被查询。这个限制在 ES 安全层强制执行,不是视图定义层面能绕过的。
1.1.2 PromQL 支持
9.4 在 ES|QL 中引入了 PROMQL 源命令(Tech Preview),允许直接在 ES|QL 管道中编写 PromQL 表达式,从存储 Prometheus 格式指标的 Elasticsearch 索引中拉取数据。这不是一个简单的代理——结果会流入 ES|QL 计算引擎,可以通过 SORT、LIMIT、WHERE 等命令进一步处理。
PROMQL index=k8s-downsampled start="2026-02-17T08:00:00Z" end="2026-02-17T09:00:00Z" step=30m
avg_bytes=(avg(rate(network.total_bytes_in[30m])))
| SORT avg_bytes DESC, step;
在写入端,新增的 POST /_prometheus/api/v1/write 端点接受标准的 Prometheus remote write 二进制协议,因此 Elasticsearch 可以作为 Prometheus 的存储后端直接使用。额外的端点覆盖了即时查询(/query)、范围查询(/query_range)、系列发现(/series)和标签枚举(/labels),全部返回标准的 Prometheus JSON 格式。
1.1.3 TSDB 合成 ID 的存储收益
TSDB 索引在时间序列模式下现在使用合成 ID 而不是索引 _id 字段。实际效果是 OTLP 指标工作负载的存储减少高达 40%,并且在段合并期间 CPU 开销降低,因为不再维护 _id 的倒排索引。
写入时的重复检测由布隆过滤器处理——轻量且快速。以前使用 _id 的查找被委托给其他索引字段,如时间戳或维度字段。查询和检索行为保持不变;该更改对现有查询是透明的。
1.1.4 向量搜索性能提升
DiskBBQ 算法获得了实质性升级。在限制性预过滤场景下,搜索性能提升 3 倍以上。新格式增加了可配置的量化位深度(1、2、4 和 7 位)、原生 SIMD 代码改进,以及通过专家 API 条件化非 IID 向量的方法。bbq_disk(DiskBBQ)现在是新索引的默认量化模式。
// semantic_text 现在默认使用 bfloat16 + bbq_disk
// 无需映射更改;新索引自动获得此优化
PUT my-index
{
"mappings": {
"properties": {
"content": { "type": "semantic_text" }
}
}
}
对于 ARM 和 x86,原生内核获得了专门的优化:AVX-512 int8 内核带级联展开、ARM NEON 上 int7u/int8 的 vdotq_s32、BBQ Int4 的 SVE 函数,以及新的 bfloat16 专用和字节向量评分器。零拷贝 SIMD 向量评分现在也在冻结层(可搜索快照)上启用。
1.2 整体架构
ElasticSearch 是一个分布式 RESTful 搜索与分析引擎,基于 Apache Lucene 构建。理解其架构层次是掌握后续所有优化技巧的基础。
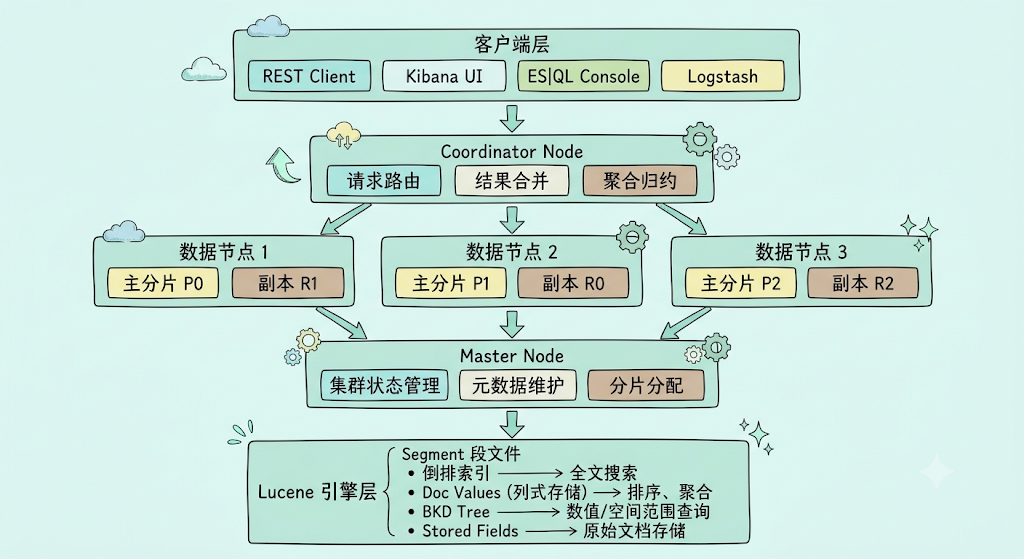
集群中的节点按角色分工:
- 主节点 (Master Node):负责管理集群状态和元数据(索引创建、分片分配、节点上下线)。生产环境建议配置 3 个专用主节点保证选举多数。
- 数据节点 (Data Node):存储实际数据并执行增删改查。可以根据数据温度进一步细分为 hot/warm/cold 节点。
- 协调节点 (Coordinator Node):接收客户端请求,将查询分发到对应分片并合并结果。可以专用节点(
node.roles: [])或由数据节点兼任。
在小型集群中,一个节点可以同时承担多个角色,但生产环境建议角色分离,避免资源争抢。
1.3 倒排索引:搜索的基石
ElasticSearch 的全文搜索能力建立在 Lucene 的倒排索引之上。与传统数据库的 B-Tree 按"行→列"存储不同,倒排索引按"词→文档列表"存储,这使得基于关键词的检索复杂度与文档总量无关,只与匹配结果数量相关。
倒排索引的构建过程:
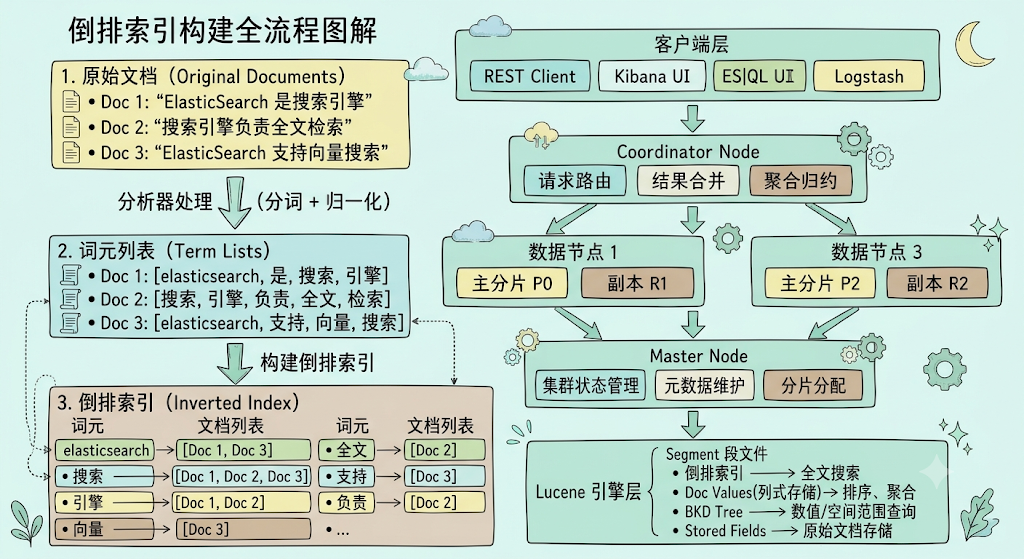
原始文档:
Doc 1: "ElasticSearch 是搜索引擎"
Doc 2: "搜索引擎负责全文检索"
Doc 3: "ElasticSearch 支持向量搜索"
↓ 分析器处理(分词 + 归一化)
词元列表:
Doc 1: [elasticsearch, 是, 搜索, 引擎]
Doc 2: [搜索, 引擎, 负责, 全文, 检索]
Doc 3: [elasticsearch, 支持, 向量, 搜索]
↓ 构建倒排索引
倒排索引:
elasticsearch → [Doc1, Doc3]
搜索 → [Doc1, Doc2, Doc3]
引擎 → [Doc1, Doc2]
向量 → [Doc3]
全文 → [Doc2]
...
分析器在写入时将文本拆分为词元并归一化(小写化、词干提取、停用词过滤等),查询时对查询文本做同样的处理,确保两侧匹配。理解这一点对索引映射设计和查询性能优化至关重要——错误的分词策略会导致"搜得到"但"搜不准"。
1.3.1 倒排索引的内部结构
一个完整的倒排索引由以下几部分组成:
| 组成部分 | 说明 | 示例 |
|---|---|---|
| Term Dictionary(词典) | 所有词元的有序列表,存储在内存中 | [elasticsearch, 搜索, 引擎, ...] |
| Term Index(词索引) | 词典的索引结构(FST),快速定位词元在词典中的位置 | 类似 Trie 树的前缀压缩结构 |
| Posting List(倒排表) | 每个词元对应的文档 ID 列表,使用 Roaring Bitmap 压缩 | elasticsearch → [1, 3] |
| Positions(位置信息) | 词元在文档中的位置,用于短语查询 | 搜索 → Doc1:pos2, Doc2:pos0 |
| Offsets(偏移信息) | 词元在原文中的起止字符位置,用于高亮 | 搜索 → Doc1:[6,8] |
| Payloads(负载) | 每个词元的附加信息,如自定义权重 | 可选,不常用 |
Roaring Bitmap 压缩:Posting List 中的文档 ID 不是简单的数组,而是使用 Roaring Bitmap 进行压缩。它将文档 ID 分为高 16 位和低 16 位,高 16 位作为容器索引,低 16 位根据密度选择 Array Container(稀疏)或 Bitmap Container(密集)存储。这种设计在保持快速随机访问的同时大幅减少内存占用。
1.3.2 BKD Tree 与 Doc Values
除了倒排索引,Lucene 还维护几种重要数据结构:
BKD Tree:用于数值、地理空间和 IP 字段的范围查询与排序。BKD Tree 是一种多维空间索引结构,特别适合范围查询和最近邻搜索。数值字段(integer、long、float、double、date)默认使用 BKD Tree 索引。
Doc Values:列式存储,用于排序、聚合和脚本访问字段值。倒排索引擅长"词→文档"的正向查找,但不擅长"文档→字段值"的反向查找。Doc Values 弥补了这一缺陷,按文档 ID 顺序存储每个字段的值,使得聚合和排序操作不需要扫描倒排索引。Doc Values 默认对除 text 外的所有字段开启,关闭不需要的字段可节省磁盘空间和堆内存。
// 关闭不需要排序/聚合的字段的 doc_values
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false // 仅用于过滤,不需要聚合
}
}
}
}
1.3.3 FST(Finite State Transducer)词典压缩
Lucene 的 Term Dictionary 使用 FST(有限状态转换器)结构存储。FST 是一种有向无环图,能够高效压缩大量字符串同时支持前缀查询。它的优势在于:
- 内存效率:百万级词元只需几十 MB 内存
- 前缀查询:天然支持前缀匹配,是
prefix查询和completion建议器的基础 - 共享前缀/后缀:相似词元自动共享路径,压缩率极高
第二章 核心概念与快速入门
2.1 安装与启动
2.1.1 Docker 方式(推荐用于开发测试)
# 创建 docker 网络
docker network create elastic
# 启动 ElasticSearch 9.4
docker run -d \
--name es \
--net elastic \
-p 9200:9200 \
-e discovery.type=single-node \
-e xpack.security.enabled=false \
-e ES_JAVA_OPTS="-Xms2g -Xmx2g" \
docker.elastic.co/elasticsearch/elasticsearch:9.4.3
# 启动 Kibana
docker run -d \
--name kibana \
--net elastic \
-p 5601:5601 \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
docker.elastic.co/kibana/kibana:9.4.3
启动后访问 http://localhost:9200 确认集群状态,Kibana 在 http://localhost:5601 提供 Dev Tools 控制台用于交互式查询。
2.1.2 生产环境部署(APT 仓库)
# 1. 导入 GPG 密钥
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# 2. 添加仓库
echo "deb https://artifacts.elastic.co/packages/9.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-9.x.list
# 3. 安装
sudo apt-get update && sudo apt-get install elasticsearch
# 4. 配置 JVM 堆内存(/etc/elasticsearch/jvm.options)
# -Xms16g
# -Xmx16g
# 5. 配置 elasticsearch.yml
cat > /etc/elasticsearch/elasticsearch.yml << 'EOF'
cluster.name: my-cluster
node.name: node-1
network.host: 0.0.0.0
discovery.seed_hosts: ["host1", "host2", "host3"]
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
EOF
# 6. 启动
sudo systemctl enable elasticsearch
sudo systemctl start elasticsearch
生产环境务必开启安全认证(xpack.security.enabled=true)并配置 TLS。
2.1.3 集群健康检查
# 查看集群健康状态
curl -X GET "localhost:9200/_cluster/health?pretty"
# 响应示例
{
"cluster_name": "my-cluster",
"status": "green", // green=健康, yellow=副本缺失, red=主分片缺失
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 15,
"active_shards": 30,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0
}
2.2 核心概念速览
| 概念 | 关系型数据库类比 | 说明 |
|---|---|---|
| Index(索引) | Database / Table | 文档的集合,7.x 后一个索引对应一种类型 |
| Document(文档) | Row | JSON 格式的数据单元,通过 _id 唯一标识 |
| Field(字段) | Column | 文档中的键值对,有明确的数据类型 |
| Mapping(映射) | Schema | 定义字段的类型、分析器等配置 |
| Shard(分片) | Partition | 索引的水平拆分单元,分主分片和副本 |
| Segment(段) | - | Lucene 中的不可变存储单元,倒排索引的物理载体 |
| Replica(副本) | Read Replica | 主分片的拷贝,提供高可用和读取负载均衡 |
| Alias(别名) | View | 指向一个或多个索引的软链接,用于零停机重建索引 |
关键区分:Shard 是 ElasticSearch 层面的路由单元(决定文档存哪个节点),Segment 是 Lucene 层面的存储单元(实际的倒排索引文件)。一次写入先进入内存缓冲区,refresh 后生成新的 Segment,merge 后合并为更大的 Segment。
2.2.1 分片的工作机制
每个分片本质上是一个独立的 Lucene 索引,拥有完整的倒排索引、Doc Values 等数据结构。文档写入时,ElasticSearch 根据以下公式路由文档到对应分片:
shard = hash(routing) % number_of_primary_shards
其中 routing 默认是文档的 _id,也可以自定义。这意味着主分片数量在索引创建后无法修改(只能 reindex 到新索引),因为修改后路由结果会变化,原有文档将无法被找到。
2.2.2 写入流程详解
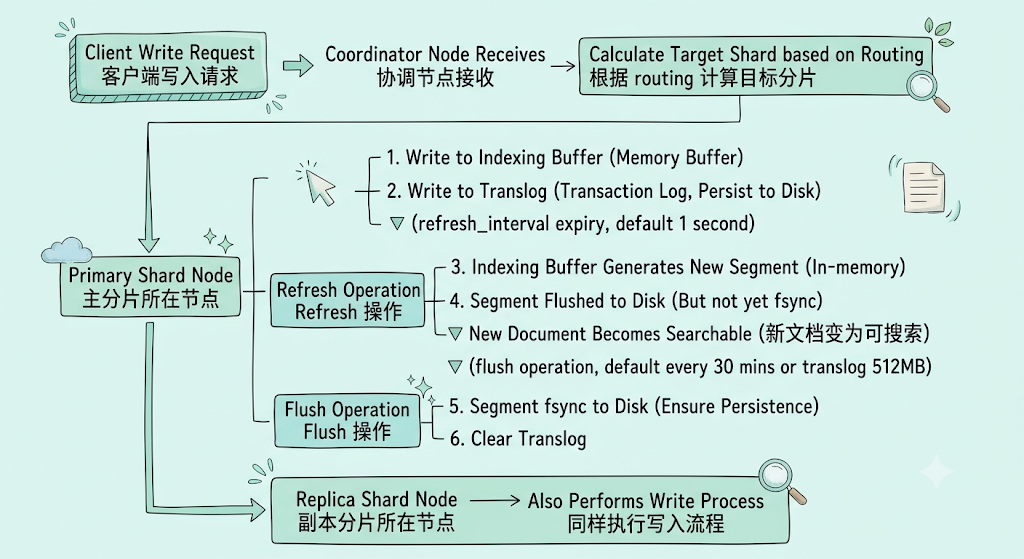
客户端写入请求
│
▼
协调节点接收 ──→ 根据 routing 计算目标分片
│
▼
主分片所在节点
│
├──→ 1. 写入 Indexing Buffer(内存缓冲区)
├──→ 2. 写入 Translog(事务日志,持久化到磁盘)
│
▼ (refresh_interval 到期,默认 1 秒)
│
Refresh 操作
│
├──→ 3. Indexing Buffer 生成新的 Segment(内存中)
├──→ 4. Segment 刷新到磁盘(但尚未 fsync)
│
▼ 新文档变为可搜索
│
▼ (flush 操作,默认每 30 分钟或 translog 达到 512MB)
│
Flush 操作
│
├──→ 5. Segment fsync 到磁盘(确保持久化)
├──→ 6. 清空 Translog
│
▼ (同时,主分片将写入同步到副本分片)
│
副本分片所在节点
│
└──→ 同样执行写入流程
关键时间点:
- refresh(1 秒):新文档变为可搜索。这是 ElasticSearch "近实时"的来源。
- flush(30 分钟或 512MB translog):确保数据持久化到磁盘。
- translog:在 flush 之前,通过 translog 保证崩溃恢复时不丢失数据。
2.3 第一次索引与查询
2.3.1 创建索引并定义映射
PUT /products
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "1s"
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": { "type": "keyword" }
}
},
"price": { "type": "scaled_float", "scaling_factor": 100 },
"category": { "type": "keyword" },
"tags": { "type": "keyword" },
"create_time": { "type": "date" },
"description": { "type": "text", "analyzer": "ik_max_word" }
}
}
}
字段说明:
name使用text类型支持全文搜索,同时通过fields.keyword子字段支持精确匹配和聚合排序price使用scaled_float而非double,内部以 long 存储(乘以 scaling_factor),避免浮点精度问题且节省空间category和tags使用keyword类型,不分词,适合精确过滤和聚合create_time使用date类型,支持范围查询和日期直方图聚合
2.3.2 批量写入文档
POST /_bulk
{ "index": { "_index": "products", "_id": "1" } }
{ "name": "ElasticSearch 实战指南", "price": 89.90, "category": "图书", "tags": ["技术", "搜索"], "create_time": "2026-06-01" }
{ "index": { "_index": "products", "_id": "2" } }
{ "name": "无线蓝牙耳机 Pro", "price": 599.00, "category": "数码", "tags": ["音频", "无线"], "create_time": "2026-06-15" }
{ "index": { "_index": "products", "_id": "3" } }
{ "name": "机械键盘 RGB 背光", "price": 329.00, "category": "数码", "tags": ["外设", "机械"], "create_time": "2026-07-01" }
Bulk API 是最高效的批量写入方式,一次请求可以包含多个 index/update/delete 操作。每行是一个操作指令,下一行是对应的数据体。
2.3.3 执行全文搜索查询
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "无线 耳机" } }
],
"filter": [
{ "range": { "price": { "lte": 1000 } } }
]
}
},
"sort": [
{ "_score": "desc" },
{ "create_time": "desc" }
],
"size": 10
}
这个查询展示了 ElasticSearch 查询的核心模式:bool 组合查询中 must 用于全文匹配并计算相关性得分,filter 用于精确过滤且不参与打分。filter 上下文的结果会被节点级缓存,相同条件的后续查询直接命中缓存,延迟显著降低。
2.3.4 常用 REST API 速查
| 操作 | 方法 | 路径 | 说明 |
|---|---|---|---|
| 创建索引 | PUT | /{index} |
创建索引并可选定义映射 |
| 删除索引 | DELETE | /{index} |
删除索引及其所有数据 |
| 查看映射 | GET | /{index}/_mapping |
查看索引的字段映射 |
| 修改设置 | PUT | /{index}/_settings |
修改索引的动态设置 |
| 写入文档 | POST | /{index}/_doc |
自动生成 _id |
| 写入文档 | PUT | /{index}/_doc/{id} |
指定 _id |
| 获取文档 | GET | /{index}/_doc/{id} |
按 _id 获取单个文档 |
| 更新文档 | POST | /{index}/_update/{id} |
部分更新 |
| 删除文档 | DELETE | /{index}/_doc/{id} |
按 _id 删除 |
| 批量操作 | POST | /_bulk |
批量 index/update/delete |
| 搜索 | GET/POST | /{index}/_search |
执行查询 |
| 聚合统计 | GET | /{index}/_count |
文档计数 |
| 强制合并 | POST | /{index}/_forcemerge |
合并 Segment |
| 刷新 | POST | /{index}/_refresh |
强制 refresh |
第三章 索引设计与映射
映射是性能的起点——错误的字段类型选择会在集群规模扩大后变成无法修复的债务。
3.1 字段类型选择策略
ElasticSearch 提供了丰富的字段类型,选择正确的类型直接影响存储效率、查询性能和功能可用性。
3.1.1 核心类型决策表
| 场景 | 推荐类型 | 原因 |
|---|---|---|
| 全文搜索(商品名称、文章标题) | text + keyword 子字段 |
text 支持分词检索,keyword 支持精确匹配和聚合排序 |
| 精确值(状态、分类、标签) | keyword |
不分词,倒排索引体积小,聚合快 |
| 金额价格 | scaled_float |
用 long 存储,避免浮点精度问题,比 double 节省空间 |
| 整数计数器(有范围查询需求) | integer / long |
支持 range 查询,BKD Tree 索引 |
| 自增 ID(无范围查询需求) | keyword |
keyword 查询比 numeric 更快 |
| 时间戳 | date |
支持范围查询和日期直方图聚合 |
| 布尔值 | boolean |
存储为单字节,查询效率高 |
| IP 地址 | ip |
支持 CIDR 范围查询 |
| 嵌套对象(需要独立查询) | nested |
保持对象间的关系,避免扁平化导致的交叉匹配 |
| 大对象(不需索引) | object + enabled: false |
仅存储不索引,节省空间 |
| 地理坐标点 | geo_point |
支持距离查询和边界框查询 |
| 地理形状 | geo_shape |
支持复杂多边形查询 |
| 二进制数据 | binary |
Base64 存储,不索引 |
3.1.2 数值类型详解
┌─────────────────┬──────────┬────────────────────────────────────────┐
│ 类型 │ 大小 │ 适用场景 │
├─────────────────┼──────────┼────────────────────────────────────────┤
│ byte │ 1 字节 │ -128 到 127 │
│ short │ 2 字节 │ -32768 到 32767 │
│ integer │ 4 字节 │ 通用整数,计数器、年龄 │
│ long │ 8 字节 │ 大整数,时间戳(内部存储) │
│ float │ 4 字节 │ 单精度浮点,对精度要求不高 │
│ double │ 8 字节 │ 双精度浮点 │
│ scaled_float │ 8 字节 │ 金额、评分(long + scaling_factor) │
│ unsigned_long │ 8 字节 │ 0 到 2^64-1,无符号长整型 │
└─────────────────┴──────────┴────────────────────────────────────────┘
为什么金额用 scaled_float 而不是 double?
scaled_float 内部以 long 存储,值 = 原始值 × scaling_factor。例如价格 89.90 元,scaling_factor=100,存储为 8990。好处是:
- long 比 double 节省空间(相同位数下 long 不需要存储指数部分)
- 整数比较比浮点数比较快
- 避免浮点精度问题(0.1 + 0.2 ≠ 0.3 的问题)
- BKD Tree 对整数索引效率更高
3.1.3 dynamic mapping 的陷阱
ElasticSearch 默认开启动态映射,字符串字段会被自动映射为 text + keyword 双字段。这意味着每个字符串字段都同时建立了倒排索引和 BKD Tree,在字段数量多的场景下(如日志)会导致映射爆炸和磁盘浪费。
// 默认行为:每个字符串字段都被双重索引
PUT /logs-default
{ "mappings": { "dynamic": true } }
POST /logs-default/_doc
{
"service": "api-gateway", // 被映射为 text + keyword
"env": "production", // 被映射为 text + keyword
"request_id": "abc123", // 被映射为 text + keyword
"user_agent": "Mozilla/5.0..." // 被映射为 text + keyword
}
// 结果:4 个字符串字段 × 2 种索引 = 8 份索引数据
// 大部分字段只需要 keyword 精确匹配,text 索引是浪费
解决方案:
// 方案 1:严格模式,拒绝未知字段
PUT /logs-strict
{
"mappings": {
"dynamic": "strict" // 写入未定义字段会报错
}
}
// 方案 2:动态模板,精确控制类型推断
PUT /logs-template
{
"mappings": {
"dynamic": "true",
"dynamic_templates": [
{
"strings_as_keyword": {
"match_mapping_type": "string",
"mapping": { "type": "keyword", "ignore_above": 256 }
}
}
]
}
}
3.2 分析器配置
分析器(Analyzer)是全文搜索的核心组件,负责将文本拆分为词元(Token)并归一化。一个分析器由三部分组成:
Character Filter(字符过滤器)
│ 处理原始文本,如去除 HTML 标签
▼
Tokenizer(分词器)
│ 将文本拆分为词元
▼
Token Filter(词元过滤器)
│ 对词元进行归一化处理
│ 如小写化、词干提取、停用词过滤
▼
最终词元列表
3.2.1 内置分析器
| 分析器 | 行为 | 示例输入 → 输出 |
|---|---|---|
standard |
基于 Unicode 文本分割,小写化 | “Hello World” → [hello, world] |
simple |
按非字母分割,小写化 | “Hello-World 123” → [hello, world] |
whitespace |
按空白分割 | “Hello World” → [Hello, World] |
keyword |
不分词,整体作为一个词元 | “Hello World” → [Hello World] |
stop |
standard + 停用词过滤 | “The quick fox” → [quick, fox] |
pattern |
按正则表达式分割 | “foo,bar;baz” → [foo, bar, baz] |
language |
特定语言分析器(english 等) | “running” → [run](词干提取) |
3.2.2 中文分词:IK 分词器
中文全文搜索需要借助 IK 分词器或 jieba 分词器。IK 提供两种分词模式:
ik_max_word(最细粒度分词):尽可能多地切分词元,适合索引时使用,提高召回率ik_smart(智能分词):减少歧义切分,适合查询时使用,提高精确率
输入文本: "ElasticSearch 搜索引擎实战"
ik_max_word: [elasticsearch, 搜索, 搜索引擎, 引擎, 实战]
ik_smart: [elasticsearch, 搜索引擎, 实战]
自定义分析器:索引时细粒度,查询时智能
PUT /articles
{
"settings": {
"analysis": {
"analyzer": {
"ik_index": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["lowercase", "asciifolding"]
},
"ik_search": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["lowercase", "asciifolding"]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_index",
"search_analyzer": "ik_search"
},
"content": {
"type": "text",
"analyzer": "ik_index",
"search_analyzer": "ik_search"
}
}
}
}
索引时使用 ik_max_word 尽可能多地切分词元,提高召回率;查询时使用 ik_smart 减少歧义,提高精确率。这种"索引细、查询粗"的策略是中文搜索的标准实践。
3.2.3 验证分析器输出
使用 _analyze API 可以查看分析器对特定文本的处理结果,是调试分词问题的重要工具:
// 查看分析器输出
POST /articles/_analyze
{
"analyzer": "ik_max_word",
"text": "ElasticSearch 搜索引擎实战"
}
// 响应
{
"tokens": [
{ "token": "elasticsearch", "start_offset": 0, "end_offset": 13, "type": "ENGLISH", "position": 0 },
{ "token": "搜索", "start_offset": 14, "end_offset": 16, "type": "CN_WORD", "position": 1 },
{ "token": "搜索引擎", "start_offset": 14, "end_offset": 18, "type": "CN_WORD", "position": 2 },
{ "token": "引擎", "start_offset": 16, "end_offset": 18, "type": "CN_WORD", "position": 3 },
{ "token": "实战", "start_offset": 18, "end_offset": 20, "type": "CN_WORD", "position": 4 }
]
}
3.2.4 自定义同义词过滤器
搜索场景中经常需要处理同义词,如"手机"和"智能手机"、“耳机"和"耳麦”:
PUT /products-synonym
{
"settings": {
"analysis": {
"filter": {
"my_synonym": {
"type": "synonym",
"synonyms": [
"手机,智能手机,移动电话",
"耳机,耳麦,耳塞",
"电脑,计算机,PC"
]
}
},
"analyzer": {
"ik_with_synonym": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["lowercase", "my_synonym"]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_with_synonym"
}
}
}
}
配置后,搜索"手机"时也会匹配到包含"智能手机"或"移动电话"的文档。
3.3 动态模板
当日志类数据字段不固定时,动态模板可以按规则自动推断字段类型,避免映射爆炸:
PUT /logs-app
{
"mappings": {
"dynamic": "true",
"dynamic_templates": [
{
"strings_as_keyword": {
"match_mapping_type": "string",
"mapping": { "type": "keyword", "ignore_above": 256 }
}
},
{
"longs_as_long": {
"match_mapping_type": "long",
"mapping": { "type": "long" }
}
},
{
"doubles_as_double": {
"match_mapping_type": "double",
"mapping": { "type": "double" }
}
},
{
"dates_as_date": {
"match": ".*_time$",
"mapping": { "type": "date" }
}
},
{
"booleans_as_boolean": {
"match_mapping_type": "boolean",
"mapping": { "type": "boolean" }
}
}
]
}
}
这个模板将所有自动发现的字符串映射为 keyword(截断超过 256 字符的值),以 _time 结尾的字段映射为 date。对于日志场景,大部分字符串字段只需要精确匹配,不需要分词全文搜索,这样可以显著减少倒排索引体积。
动态模板的匹配规则:
| 匹配方式 | 说明 | 示例 |
|---|---|---|
match_mapping_type |
按 JSON 类型匹配 | "string", "long", "double", "object", "boolean" |
match |
按字段名正则匹配 | ".*_time$" 匹配所有以 _time 结尾的字段 |
unmatch |
排除匹配的字段 | 排除特定模式 |
path_match |
按完整路径匹配 | "user.*.name" 匹配嵌套字段 |
match_pattern |
匹配模式类型 | "regex" 或 "simple" |
3.4 nested 与 join 类型
3.4.1 普通对象的问题
普通 object 类型会将嵌套数组扁平化存储,导致跨对象字段的交叉匹配:
// 写入的文档
{
"user": [
{ "first": "张", "last": "三" },
{ "first": "李", "last": "四" }
]
}
// ElasticSearch 内部存储(扁平化)
{
"user.first": ["张", "李"],
"user.last": ["三", "四"]
}
// 查询 first=张 AND last=四 会错误地匹配到这条文档
// 因为 "张" 在 user.first 数组中,"四" 在 user.last 数组中
3.4.2 使用 nested 类型
使用 nested 类型可以保持对象内部的独立性:
PUT /users
{
"mappings": {
"properties": {
"user": {
"type": "nested",
"properties": {
"first": { "type": "keyword" },
"last": { "type": "keyword" }
}
}
}
}
}
nested 类型将每个嵌套对象作为独立文档存储(hidden document),查询时通过 join 关联。这意味着 100 个嵌套对象会产生 101 个 Lucene 文档。
// nested 查询
GET /users/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "term": { "user.first": "张" } },
{ "term": { "user.last": "三" } }
]
}
}
}
}
}
nested 的代价:在嵌套层级深或数组长的场景下,查询性能会显著下降。如果只需要存储不需要按嵌套对象查询,用普通
object即可;如果需要父子文档的复杂关联操作,考虑join类型或应用层关联。
3.4.3 join 类型(父子文档)
join 类型定义了文档间的父子关系,父文档和子文档存储在同一个索引中:
PUT /company
{
"mappings": {
"properties": {
"relation": {
"type": "join",
"relations": {
"department": "employee"
}
}
}
}
}
// 写入父文档
PUT /company/_doc/1
{
"name": "技术部",
"relation": "department"
}
// 写入子文档(指定父 ID)
PUT /company/_doc/2?routing=1
{
"name": "张三",
"relation": { "name": "employee", "parent": "1" }
}
// 查询某部门的所有员工
GET /company/_search
{
"query": {
"has_parent": {
"parent_type": "department",
"query": { "term": { "name": "技术部" } }
}
}
}
join 类型的限制:父子文档必须路由到同一个分片(通过 routing),每次查询需要 join 操作,性能较差。只有在真正需要父子关系时才使用,否则推荐使用嵌套文档或应用层关联。
3.5 索引别名与零停机重建
索引别名是指向一个或多个索引的软链接,是生产环境不可或缺的工具:
// 创建别名
POST /_aliases
{
"actions": [
{ "add": { "index": "products_v1", "alias": "products" } }
]
}
// 通过别名读写(对应用透明)
POST /products/_doc // 实际写入 products_v1
GET /products/_search // 实际查询 products_v1
// 零停机重建索引
POST /_aliases
{
"actions": [
{ "add": { "index": "products_v2", "alias": "products" } },
{ "remove": { "index": "products_v1", "alias": "products" } }
]
}
别名的高级用法:
// 写入别名:只指向一个索引
POST /_aliases
{
"actions": [
{ "add": { "index": "products_v2", "alias": "products_write" } }
]
}
// 查询别名:可以指向多个索引
POST /_aliases
{
"actions": [
{ "add": { "indices": ["products_v1", "products_v2"], "alias": "products_read" } }
]
}
// 过滤别名:只暴露部分数据
POST /_aliases
{
"actions": [
{
"add": {
"index": "products",
"alias": "products_onsale",
"filter": { "term": { "status": "on_sale" } }
}
}
]
}
第四章 索引优化实战
从分片策略到写入吞吐,系统性地优化索引层性能。
4.1 分片策略设计
分片数量是索引创建后无法修改(只能 reindex)的关键决策。分片过多导致每个分片体积小、元数据开销大、查询扇出多;分片过少导致单分片体积大、查询慢、故障恢复慢。官方指导原则是每个主分片控制在 10-50 GB,文档数不超过 2 亿。
分片数量对查询性能的影响:
分片大小 查询延迟(100万文档,match查询)
──────────────────────────────────────────────
5 GB 8 ms ← 过多分片,扇出开销大
10 GB 12 ms
20 GB 18 ms
30 GB 25 ms ← 最优区间
50 GB 42 ms
80 GB 85 ms
100 GB 130 ms
150 GB 280 ms ← 过大,单分片查询慢
分片数量的计算公式:主分片数 = 预估总数据量 / 目标单分片大小。例如预计 300 GB 数据,目标单分片 30 GB,则主分片数 = 10。
| 数据规模 | 推荐主分片数 | 副本数 | 说明 |
|---|---|---|---|
| < 10 GB | 1 | 1 | 小数据无需分片,避免分片开销 |
| 10-100 GB | 2-3 | 1 | 按 30-50 GB 单分片规划 |
| 100 GB-1 TB | 5-20 | 1-2 | 考虑 ILM 滚动策略配合 |
| > 1 TB | ILM 管理 | 1-2 | 使用数据流 + 滚动索引 |
过度分片的代价:每个分片都是一个独立的 Lucene 索引,消耗堆内存(约 50 KB 元数据/分片)、文件句柄和 CPU 资源。一个集群有数万分片时,主节点的集群状态发布会成为瓶颈。规则:每 GB 堆内存不超过 20 个分片。
4.1.1 分片分配过滤
可以通过分片分配过滤将特定索引分配到特定节点,实现冷热分离:
// 节点配置(elasticsearch.yml)
// hot 节点:node.attr.data_type: hot
// warm 节点:node.attr.data_type: warm
// cold 节点:node.attr.data_type: cold
// 索引级分片分配过滤
PUT /logs-2026.07/_settings
{
"index.routing.allocation.require.data_type": "hot"
}
// 通过 ILM 自动迁移
// hot 阶段 → warm 阶段时自动修改 allocation 规则
4.1.2 分片均衡
ElasticSearch 内置分片均衡器,基于两个阈值:
cluster.routing.allocation.balance.shard(默认 0.45):节点间分片数均衡cluster.routing.allocation.balance.index(默认 0.55):同一索引的分片在节点间均衡
当节点 disk usage 超过 cluster.routing.allocation.disk.watermark.high(默认 90%)时,新分片不会分配到该节点;超过 flood_stage(默认 95%)时,索引被标记为只读。
// 调整磁盘水位线
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.disk.watermark.low": "85%",
"cluster.routing.allocation.disk.watermark.high": "90%",
"cluster.routing.allocation.disk.watermark.flood_stage": "95%"
}
}
4.2 写入优化
4.2.1 批量写入与 refresh_interval
ElasticSearch 默认每秒 refresh 一次,将内存缓冲区的新文档生成新的 Segment 使其可搜索。每次 refresh 都会创建新 Segment,频繁 refresh 会导致 Segment 数量膨胀、合并压力大、写入吞吐下降。批量写入场景下应临时调大 refresh_interval 或关闭 refresh。
// 批量导入前:关闭 refresh
PUT /products/_settings
{
"refresh_interval": "-1",
"number_of_replicas": 0
}
// 执行批量导入... 使用 _bulk API,每批 5-15 MB
// 导入完成后:恢复设置
PUT /products/_settings
{
"refresh_interval": "1s",
"number_of_replicas": 1
}
// 手动触发 force merge,减少 Segment 数量
POST /products/_forcemerge?max_num_segments=1
批量导入时临时将副本数设为 0 可以避免写入时同步副本的开销,导入完成后再恢复。force merge 将多个小 Segment 合并为一个大 Segment,减少查询时需要扫描的 Segment 数量。
4.2.2 Bulk API 批量大小
Bulk 请求的理想大小在 5-15 MB 之间。过小导致网络和请求开销占比高,过大导致内存压力和超时。
# Python 示例:自适应批量大小
from elasticsearch import Elasticsearch, helpers
es = Elasticsearch(["http://localhost:9200"])
def generate_docs():
for i in range(1000000):
yield {
"_index": "products",
"_id": str(i),
"_source": {
"name": f"商品 {i}",
"price": round(random.uniform(10, 999), 2),
"category": random.choice(["数码", "图书", "家居"])
}
}
# chunk_size 控制每批文档数,max_chunk_bytes 控制每批字节上限
helpers.bulk(es, generate_docs(), chunk_size=1000, max_chunk_bytes=15*1024*1024)
Java 示例:使用 BulkProcessor
BulkProcessor bulkProcessor = BulkProcessor.builder(
client,
new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionId, BulkRequest request) {
// 批量请求前的回调
}
@Override
public void afterBulk(long executionId, BulkRequest request, BulkResponse response) {
// 批量请求成功后的回调
if (response.hasFailures()) {
logger.warn("Bulk has failures: {}", response.buildFailureMessage());
}
}
@Override
public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
// 批量请求失败后的回调
logger.error("Bulk failed", failure);
}
})
.setBulkActions(1000) // 每 1000 条触发一次
.setBulkSize(new ByteSizeValue(15, ByteSizeUnit.MB)) // 每 15MB 触发一次
.setFlushInterval(TimeValue.timeValueSeconds(5)) // 每 5 秒触发一次
.setConcurrentRequests(4) // 允许 4 个并发请求
.setBackoffPolicy(BackoffPolicy.exponentialBackoff(
TimeValue.timeValueMillis(100), 3)) // 指数退避重试
.build();
// 使用
for (Product product : products) {
bulkProcessor.add(new IndexRequest("products")
.id(product.getId())
.source(JSON.toJSONString(product), XContentType.JSON));
}
// 关闭时刷新剩余请求
bulkProcessor.awaitClose(10, TimeUnit.MINUTES);
4.2.3 写入一致性保障
| 参数 | 说明 | 推荐值 |
|---|---|---|
wait_for_active_shards |
写入前等待多少活跃分片 | 1(默认,仅主分片即可) |
index.translog.durability |
translog 持久化策略 | request(每次请求 fsync,最安全)或 async(异步,更高吞吐) |
index.translog.sync_interval |
async 模式下的同步间隔 | 5s(默认) |
index.translog.flush_threshold_size |
translog 大小触发 flush | 512mb(默认) |
// 追求写入吞吐:async 模式
PUT /products/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s",
"index.refresh_interval": "30s"
}
// 追求数据安全:request 模式(默认)
PUT /products/_settings
{
"index.translog.durability": "request"
}
4.3 Segment 合并策略
Lucene 的 TieredMergePolicy 采用分层合并策略,将大小相近的 Segment 合并在一起。
| 参数 | 默认值 | 调优建议 |
|---|---|---|
index.merge.policy.segments_per_tier |
10 | SSD 上可降到 5-7,减少 Segment 数量但增加合并 I/O |
index.merge.policy.max_merge_at_once |
10 | 单次合并最大 Segment 数,I/O 充足可调大 |
index.merge.policy.max_merged_segment |
5 GB | 合并后最大 Segment 大小,大索引可调到 10-50 GB |
index.merge.scheduler.max_thread_count |
max(1, min(4, cpu/2)) | SSD 上可调大,HDD 建议 1 |
force merge 的正确时机:对于只读索引(如历史日志、归档数据),执行
_forcemerge?max_num_segments=1将所有 Segment 合并为一个,可以显著减少查询时的 Segment 扫描数量和文件句柄占用。但运行中的索引不要 force merge 到 1 个 Segment,因为合并后无法再合并,新写入会重新产生小 Segment。
4.4 索引模板与数据流
对于时序数据(日志、指标),使用数据流(Data Stream)配合 ILM 策略是最佳实践。数据流自动管理后备索引的创建、滚动和删除。
4.4.1 完整的 ILM 策略
// 1. 创建 ILM 策略
PUT _ilm/policy/logs-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "1d",
"max_primary_shard_size": "50gb"
},
"set_priority": { "priority": 100 }
}
},
"warm": {
"min_age": "7d",
"actions": {
"shrink": { "number_of_shards": 1 },
"forcemerge": { "max_num_segments": 1 },
"set_priority": { "priority": 50 },
"allocate": {
"include": { "data_type": "warm" }
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": { "priority": 25 },
"allocate": {
"include": { "data_type": "cold" }
}
}
},
"frozen": {
"min_age": "60d",
"actions": {
"searchable_snapshot": { "snapshot_repository": "my-repo" }
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}
这个 ILM 策略实现了完整的冷热分层:
- 热阶段(0-7 天):在 SSD 上高频写入查询,按天或 50GB 滚动创建新索引
- 暖阶段(7-30 天):缩减分片数、force merge 后迁移到暖节点
- 冷阶段(30-60 天):迁移到冷节点,减少副本
- 冻结阶段(60-90 天):转为可搜索快照,极大降低存储成本
- 删除阶段(90 天后):自动删除
4.4.2 创建索引模板和数据流
// 2. 创建组件模板(settings)
PUT _component_template/logs-settings
{
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"index.lifecycle.name": "logs-policy",
"index.refresh_interval": "1s",
"index.routing.allocation.include.data_type": "hot"
}
}
}
// 3. 创建组件模板(mappings)
PUT _component_template/logs-mappings
{
"template": {
"mappings": {
"dynamic": "true",
"dynamic_templates": [
{
"strings_as_keyword": {
"match_mapping_type": "string",
"mapping": { "type": "keyword", "ignore_above": 512 }
}
}
],
"properties": {
"@timestamp": { "type": "date" },
"level": { "type": "keyword" },
"service": { "type": "keyword" },
"message": { "type": "text" }
}
}
}
}
// 4. 创建索引模板
PUT _index_template/logs-template
{
"index_patterns": ["logs-*"],
"data_stream": {},
"composed_of": ["logs-settings", "logs-mappings"],
"priority": 200
}
// 5. 写入数据自动创建数据流
POST logs-app/_doc
{ "@timestamp": "2026-07-04T10:00:00Z", "level": "info", "message": "服务启动" }
4.4.3 数据流管理命令
# 查看数据流
GET _data_stream/logs-app
# 手动滚动数据流
POST logs-app/_rollover
# 修改数据流的 ILM 策略
PUT _data_stream/logs-app
{
"index_patterns": ["logs-app-*"],
"data_stream": {},
"ilm_policy": "new-logs-policy"
}
# 删除数据流(同时删除后备索引)
DELETE _data_stream/logs-app
4.5 reindex 重建索引
当需要修改映射(如改变字段类型)或合并索引时,使用 reindex:
// 1. 创建新索引
PUT /products_v2
{
"mappings": {
"properties": {
"name": { "type": "text", "analyzer": "ik_max_word" },
"price": { "type": "scaled_float", "scaling_factor": 100 },
"category": { "type": "keyword" }
}
}
}
// 2. reindex(支持管道转换)
POST /_reindex?wait_for_completion=false
{
"source": { "index": "products" },
"dest": { "index": "products_v2" },
"script": {
"source": """
// 可以在 reindex 时做字段转换
if (ctx._source.price != null) {
ctx._source.price = ctx._source.price * 1.0;
}
// 删除不需要的字段
ctx._source.remove('internal_id');
"""
}
}
// 3. 切换别名
POST /_aliases
{
"actions": [
{ "remove": { "index": "products", "alias": "products" } },
{ "add": { "index": "products_v2", "alias": "products" } }
]
}
// 4. 删除旧索引
DELETE /products
reindex 性能优化:
// 提高批量大小
POST /_reindex?slices=auto&refresh=false
{
"source": { "index": "products", "size": 5000 },
"dest": { "index": "products_v2", "op_type": "create" }
}
// 按时间范围分批 reindex(避免一次性处理过多)
POST /_reindex
{
"source": {
"index": "products",
"query": {
"range": { "create_time": { "gte": "2026-01-01", "lt": "2026-04-01" } }
}
},
"dest": { "index": "products_v2" }
}
slices=auto 让 ElasticSearch 自动并行化 reindex,利用多核加速。op_type: create 确保不会覆盖已有文档。
第五章 查询 DSL 编写指南
从基础查询到复杂聚合,掌握查询 DSL 的完整体系与编写技巧。
5.1 查询上下文与过滤上下文
ElasticSearch 查询分为两种上下文,理解它们的区别是编写高效查询的前提。
| 维度 | Query Context(查询上下文) | Filter Context(过滤上下文) |
|---|---|---|
| 相关性打分 | 计算 _score,结果按相关性排序 | 不计算 _score,只判断是否匹配 |
| 缓存 | 不缓存(得分依赖查询词) | 结果被节点级缓存,相同条件命中快 |
| 适用场景 | 全文搜索、相关性排序 | 精确过滤、范围筛选、状态判断 |
| 典型查询 | match、multi_match、bool/must | term、terms、range、bool/filter |
| 性能 | 较慢(需要计算 BM25 得分) | 快(位图运算 + 缓存) |
核心原则:不需要相关性得分的条件一律放在
filter子句中。这是查询优化最重要的单一原则,可以同时获得"不打分"和"被缓存"两重加速。
// 好的做法:filter 中的条件稳定且可缓存
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "耳机" } }
],
"filter": [
{ "term": { "category": "数码" } },
{ "range": { "price": { "gte": 100, "lte": 2000 } } }
]
}
}
}
// 避免的做法:将不需要打分的条件放在 must 中
{
"query": {
"bool": {
"must": [
{ "match": { "name": "耳机" } },
{ "term": { "category": "数码" } }, // 浪费:不需要打分
{ "range": { "price": { "gte": 100 } } } // 浪费:不被缓存
]
}
}
}
5.2 全文搜索查询
5.2.1 match 查询
match 是最常用的全文搜索查询。对于中文,查询文本会经过与索引相同的分析器处理:
// 基本匹配:查询文本被分词后做 OR 匹配
GET /products/_search
{
"query": {
"match": { "name": "无线蓝牙耳机" }
}
}
// 要求所有词都匹配(AND)
{
"query": {
"match": {
"name": {
"query": "无线 蓝牙 耳机",
"operator": "and"
}
}
}
}
// minimum_should_match 控制最少匹配词数
{
"query": {
"match": {
"description": {
"query": "高清 无线 蓝牙 降噪 耳机",
"minimum_should_match": "75%"
}
}
}
}
// 使用 fuzziness 支持拼写纠错
{
"query": {
"match": {
"name": {
"query": "蓝芽耳机",
"fuzziness": "AUTO"
}
}
}
}
match 查询的参数详解:
| 参数 | 说明 | 示例值 |
|---|---|---|
query |
查询文本 | "无线 耳机" |
operator |
词元间的逻辑关系 | "or"(默认)、"and" |
minimum_should_match |
最少匹配的词元数 | "1"、"75%"、"2<75%" |
analyzer |
覆盖字段的分析器 | "ik_smart" |
fuzziness |
模糊匹配程度 | "AUTO"、"0"、"1"、"2" |
prefix_length |
模糊匹配时不变形的前缀长度 | 1 |
max_expansions |
模糊匹配的最大扩展数 | 50 |
zero_terms_query |
分析后无词元时的行为 | "none"(默认)、"all" |
cutoff_frequency |
高频词处理阈值(7.x 后已弃用) | - |
5.2.2 match_phrase 短语查询
当需要词序精确匹配时使用 match_phrase:
// "蓝牙耳机" 必须连续出现
{
"query": {
"match_phrase": { "name": "蓝牙耳机" }
}
}
// 允许中间间隔 1 个词
{
"query": {
"match_phrase": {
"name": { "query": "蓝牙 降噪", "slop": 1 }
}
}
}
slop 参数允许匹配的词元之间有间隔。slop=1 表示"蓝牙"和"降噪"之间可以有一个其他词。
5.2.3 multi_match 多字段查询
跨多个字段搜索时使用 multi_match,支持不同的打分策略:
GET /products/_search
{
"query": {
"multi_match": {
"query": "蓝牙耳机",
"fields": ["name^3", "description^1"],
"type": "best_fields"
}
}
}
name^3 表示 name 字段得分乘以 3 的权重提升。type 参数控制打分策略:
| type | 行为 | 适用场景 |
|---|---|---|
best_fields |
取匹配度最高字段的得分 | 同一概念分散在不同字段,取最佳匹配 |
most_fields |
累加所有匹配字段的得分 | 多字段匹配提升相关性 |
cross_fields |
将多字段视为一个字段处理 | 人名等拆分存储的场景 |
phrase |
在每个字段上做短语匹配,取最高分 | 需要词序精确的场景 |
phrase_prefix |
短语前缀匹配 | 搜索补全场景 |
bool_prefix |
匹配前缀,最后词做前缀匹配 | 搜索建议 |
5.2.4 布尔查询组合
bool 查询是 DSL 中最强大的组合工具:
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "耳机" } }
],
"should": [
{ "match": { "description": "降噪" } },
{ "term": { "tags": "蓝牙" } }
],
"filter": [
{ "range": { "price": { "gte": 100, "lte": 2000 } } },
{ "terms": { "category": ["数码", "音频"] } }
],
"must_not": [
{ "term": { "status": "discontinued" } }
],
"minimum_should_match": 1
}
}
}
| 子句 | 作用 | 是否打分 | 是否影响匹配 |
|---|---|---|---|
must |
必须匹配 | 是 | 是 |
filter |
必须匹配 | 否(缓存) | 是 |
should |
至少匹配 minimum_should_match 个 | 是 | 有 must/filter 时不影响,否则必须匹配至少 1 个 |
must_not |
必须不匹配 | 否 | 是 |
5.2.5 constant_score 查询
当你希望 filter 条件的结果有一个固定得分(而不是 0)时使用:
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"filter": { "term": { "tags": "热销" } },
"boost": 1.5
}
},
{
"match": { "name": "耳机" }
}
]
}
}
}
5.3 精确值查询
5.3.1 term 与 terms 查询
// term:精确匹配单个值(不分词)
{ "query": { "term": { "category": "数码" } } }
// terms:匹配多个值(类似 SQL IN)
{ "query": { "terms": { "category": ["数码", "音频", "外设"] } } }
// terms lookup:从另一个文档的字段获取匹配值
{
"query": {
"terms": {
"tags": {
"index": "user-preferences",
"id": "user_123",
"path": "interested_tags"
}
}
}
}
注意:
term查询对text类型字段可能不匹配预期结果,因为text字段经过分词后存储的是词元。查询text字段时应该使用match查询,或者查询.keyword子字段。
5.3.2 range 范围查询
// 数值范围
{ "query": { "range": { "price": { "gte": 100, "lte": 2000 } } } }
// 日期范围(支持数学表达式)
{
"query": {
"range": {
"create_time": {
"gte": "now-7d/d", // 7 天前的 0 点
"lt": "now/d" // 今天的 0 点
}
}
}
}
// 日期数学表达式示例
"now" // 当前时间
"now-1h" // 1 小时前
"now/d" // 今天的 0 点(舍入到天)
"now+1d/d" // 明天的 0 点
"2026-07-04||/d" // 2026-07-04 的 0 点
日期查询优化:对 date 字段做范围查询时,使用 now/1d 这样的舍入表达式可以利用查询缓存,而精确到秒的时间戳每次都不同,无法被缓存。
// 好:舍入到天,可缓存
{ "range": { "create_time": { "gte": "now/d", "lt": "now+1d/d" } } }
// 差:精确到毫秒,每次查询不同,不缓存
{ "range": { "create_time": { "gte": "2026-07-04T10:30:00.123Z" } } }
5.4 聚合查询
聚合是 ElasticSearch 作为分析引擎的核心能力。聚合分为三类:桶聚合(Bucket)、指标聚合(Metric)和管道聚合(Pipeline)。
5.4.1 桶聚合与指标聚合组合
GET /products/_search
{
"size": 0,
"query": {
"range": { "create_time": { "gte": "2026-06-01" } }
},
"aggs": {
"by_category": {
"terms": {
"field": "category",
"size": 10,
"order": { "avg_price": "desc" }
},
"aggs": {
"avg_price": { "avg": { "field": "price" } },
"price_stats": { "stats": { "field": "price" } },
"price_histogram": {
"histogram": {
"field": "price",
"interval": 200
}
}
}
}
}
}
这个查询按分类分桶,每个桶内计算平均价格、价格统计信息和价格直方图。size: 0 表示不返回文档,只返回聚合结果,减少网络传输。
5.4.2 常用指标聚合
| 聚合类型 | 说明 | 示例 |
|---|---|---|
avg |
平均值 | { "avg": { "field": "price" } } |
sum |
求和 | { "sum": { "field": "price" } } |
max / min |
最大值/最小值 | { "max": { "field": "price" } } |
stats |
统计信息(count, min, max, avg, sum) | { "stats": { "field": "price" } } |
cardinality |
去重计数(HyperLogLog) | { "cardinality": { "field": "user_id" } } |
percentiles |
百分位数 | { "percentiles": { "field": "latency", "percents": [50, 95, 99] } } |
percentile_ranks |
值的百分位排名 | { "percentile_ranks": { "field": "latency", "values": [100, 500] } } |
top_hits |
桶内 top N 文档 | { "top_hits": { "size": 3, "sort": [{ "price": "desc" }] } } |
value_count |
值计数 | { "value_count": { "field": "price" } } |
5.4.3 日期直方图聚合
{
"aggs": {
"daily_sales": {
"date_histogram": {
"field": "create_time",
"calendar_interval": "1d",
"format": "yyyy-MM-dd",
"time_zone": "+08:00",
"min_doc_count": 0
},
"aggs": {
"revenue": { "sum": { "field": "price" } }
}
}
}
}
| 时间间隔参数 | 说明 |
|---|---|
calendar_interval: "1d" |
按天(日历对齐) |
calendar_interval: "1M" |
按月(日历对齐,每月天数不同) |
fixed_interval: "30d" |
固定 30 天 |
fixed_interval: "1h" |
固定 1 小时 |
fixed_interval: "30m" |
固定 30 分钟 |
calendar_interval 按日历对齐(如按月时每月天数不同),fixed_interval 是固定的时间间隔。
5.4.4 管道聚合
管道聚合在其他聚合结果上做二次计算:
{
"aggs": {
"monthly": {
"date_histogram": {
"field": "create_time",
"calendar_interval": "1M"
},
"aggs": {
"monthly_revenue": { "sum": { "field": "price" } },
"cumulative_revenue": {
"cumulative_sum": { "buckets_path": "monthly_revenue" }
},
"mom_growth": {
"derivative": { "buckets_path": "monthly_revenue" }
}
}
}
}
}
常用管道聚合:
cumulative_sum:累计求和derivative:导数(环比变化)moving_avg:移动平均bucket_sort:桶排序avg_bucket:桶平均值
5.4.5 高基数聚合的处理
高基数聚合的陷阱:
terms聚合在高基数字段(如 user_id、IP 地址)上会生成大量桶,消耗大量内存并可能导致 OOM。解决方案:使用composite聚合分页获取所有桶,或使用cardinality聚合计算去重数(基于 HyperLogLog 算法,内存占用固定)。
// composite 聚合:分页获取高基数聚合结果
{
"size": 0,
"aggs": {
"by_user": {
"composite": {
"size": 1000,
"sources": [
{ "user": { "terms": { "field": "user_id" } } },
{ "date": { "date_histogram": { "field": "@timestamp", "calendar_interval": "1d" } } }
]
},
"aggs": {
"total_spent": { "sum": { "field": "amount" } }
}
}
}
}
// 响应中包含 after_key,用于获取下一页
// {
// "aggregations": {
// "by_user": {
// "after_key": { "user": "user_999", "date": "2026-07-01" },
// "buckets": [...]
// }
// }
// }
// 下一页查询
{
"aggs": {
"by_user": {
"composite": {
"size": 1000,
"sources": [...],
"after": { "user": "user_999", "date": "2026-07-01" }
}
}
}
}
5.5 深度分页
ElasticSearch 的 from + size 分页在深度分页时性能急剧下降——协调节点需要从每个分片取 from + size 条文档,合并排序后丢弃前 from 条。例如 from=10000, size=10,3 个分片需要各取 10010 条,协调节点处理 30030 条再丢弃 10000 条。
| 分页方式 | 适用场景 | 限制 |
|---|---|---|
from + size |
浅分页(< 10000) | index.max_result_window 默认 10000 |
search_after |
深度分页、实时翻页 | 需要排序字段唯一,不支持随机跳页 |
scroll |
批量导出全量数据 | 非实时,占用资源,9.x 后推荐用 PIT + search_after |
PIT + search_after |
推荐的全量遍历方式 | 需要先创建 PIT 保持数据快照 |
5.5.1 PIT + search_after 深度分页
// 1. 创建 PIT
POST /products/_pit?keep_alive=5m
// 返回: { "id": "pit_id_string" }
// 2. 首次查询
GET /_search
{
"size": 100,
"pit": {
"id": "上一步返回的 pit_id",
"keep_alive": "5m"
},
"query": { "match_all": {} },
"sort": [
{ "create_time": "asc" },
{ "_shard_doc": "asc" }
]
}
// 3. 后续查询:使用上一次结果的 sort 值
GET /_search
{
"size": 100,
"pit": {
"id": "pit_id",
"keep_alive": "5m"
},
"query": { "match_all": {} },
"sort": [
{ "create_time": "asc" },
{ "_shard_doc": "asc" }
],
"search_after": ["2026-07-01T00:00:00Z", 12345]
}
// 4. 用完删除 PIT
DELETE /_pit
{ "id": "pit_id" }
排序字段必须包含 _shard_doc(即 _doc)作为兜底排序,确保排序值全局唯一。PIT 提供了一致的数据快照,避免遍历过程中新写入文档导致重复或遗漏。
5.6 查询性能分析
使用 _search?profile=true 可以查看查询在每个分片上的执行细节,定位性能瓶颈:
GET /products/_search?profile=true
{
"query": {
"bool": {
"must": [{ "match": { "name": "耳机" } }],
"filter": [{ "range": { "price": { "lte": 500 } } }]
}
},
"size": 5
}
profile 输出会显示每个 query 子句的 time_in_nanos(耗时)、breakdown(各阶段耗时明细)和 children(子查询耗时)。根据这些信息可以判断是 match 查询慢还是 filter 慢,是否命中了缓存。
profile 输出的关键字段:
{
"profile": {
"shards": [
{
"id": "[index_name][0][node_id]",
"searches": [
{
"query": {
"type": "BooleanQuery",
"description": "+name:耳机 #price:[-∞ TO 500]",
"time_in_nanos": 145000,
"breakdown": {
"create_weight": 5000, // 创建查询权重
"build_scorer": 80000, // 构建 Scorer
"next_doc": 30000, // 遍历文档
"score": 15000, // 计算得分
"advance": 5000, // 跳转文档
"match_count": 0,
"compute_max_score": 0,
"shallow_advance": 10000
},
"children": [
{
"type": "TermQuery",
"description": "name:耳机",
"time_in_nanos": 80000,
"breakdown": { ... }
},
{
"type": "PointRangeQuery",
"description": "price:[-∞ TO 500]",
"time_in_nanos": 40000,
"breakdown": { ... }
}
]
}
}
]
}
]
}
}
分析方法:
- 看
time_in_nanos总耗时,找出最慢的子查询 - 看
breakdown中哪个阶段耗时最多(build_scorer高可能意味着扫描了大量文档) - 对比
match和filter的耗时分布 - 检查是否使用了
rewrite(如MultiTermQuery被重写为TermQuery的合集)
5.7 suggester 搜索建议
ElasticSearch 提供三种建议器:term suggester(词项建议)、phrase suggester(短语建议)、completion suggester(自动补全)。
5.7.1 completion suggester(自动补全)
// 索引映射
PUT /products_suggest
{
"mappings": {
"properties": {
"name": {
"type": "completion",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"preserve_separators": true,
"max_input_length": 50
}
}
}
}
// 写入建议数据
POST /products_suggest/_doc
{
"name": {
"input": ["无线蓝牙耳机", "蓝牙耳机", "无线耳机"],
"weight": 10
}
}
// 查询建议
GET /products_suggest/_search
{
"suggest": {
"product-suggest": {
"prefix": "蓝牙",
"completion": {
"field": "name",
"size": 5,
"skip_duplicates": true
}
}
}
}
completion suggester 使用 FST 结构存储,性能极高,适合搜索框自动补全场景。
第六章 ES|QL 查询语言
ElasticSearch 9.x 的一等查询语言,用管道式语法简化复杂分析。
6.1 为什么需要 ES|QL
传统的 Query DSL 是 JSON 格式,编写和阅读复杂查询时需要嵌套多层结构。ES|QL(Elasticsearch Query Language)是 ElasticSearch 8.11 引入、在 9.4 中大幅增强的管道式查询语言,语法类似 SQL 但增加了管道操作符,更适合数据探索和转换。
ES|QL 的核心优势在于管道式处理:数据从 FROM 源流出,经过一系列 | 管道命令逐步变换,每一步的输出是下一步的输入。这种线性结构比嵌套 JSON 更直观,尤其适合多步骤的数据转换和分析。
ES|QL vs Query DSL 对比:
| 维度 | Query DSL (JSON) | ES|QL |
|---|---|---|
| 语法 | 嵌套 JSON | 管道式(类似 SQL + Unix pipe) |
| 可读性 | 复杂查询难读 | 线性流程,逐步转换 |
| 执行效率 | 通用引擎 | 专用计算引擎,某些场景更快 |
| 功能 | 全功能 | 持续增强中,9.4 已覆盖大部分场景 |
| 缓存 | 节点级缓存 | 独立的计算会话 |
| 适用 | API 集成 | 数据探索、仪表盘、告警 |
6.2 基础语法
ES|QL 通过 POST /_query 端点执行,支持 text、json、csv 等多种输出格式:
// 通过 REST API 执行 ES|QL
POST /_query?format=txt
{
"query": """
FROM products
| WHERE price > 100 AND price < 1000
| KEEP name, price, category
| SORT price DESC
| LIMIT 20
"""
}
ES|QL 的关键字不区分大小写。常用管道命令:
| 命令 | 作用 | 示例 |
|---|---|---|
FROM |
指定数据源(索引、数据流、视图) | FROM products |
WHERE |
过滤行 | WHERE price > 100 |
KEEP |
保留指定列 | KEEP name, price |
DROP |
移除指定列 | DROP internal_id |
RENAME |
重命名列 | RENAME price AS unit_price |
EVAL |
计算新列 | EVAL discount = price * 0.8 |
STATS |
聚合统计(类似 SQL GROUP BY) | STATS avg = AVG(price) BY category |
SORT |
排序 | SORT price DESC |
LIMIT |
限制行数 | LIMIT 100 |
GROK |
解析非结构化文本 | GROK message "%{GREEDYDATA:msg}" |
DISSECT |
解析结构化文本 | DISSECT message "%{service} %{level} %{}" |
MV_EXPAND |
展开多值字段 | MV_EXPAND tags |
ENRICH |
关联查找 | ENRICH policy_name ON field |
6.3 全文搜索与匹配
ES|QL 支持全文搜索,使用 match 函数或 : 运算符:
// 全文匹配
FROM products
| WHERE name : "蓝牙耳机"
| KEEP name, price, category
| SORT price ASC
| LIMIT 10
// 使用 match 函数(支持更多参数)
FROM products
| WHERE match(name, "降噪 耳机")
| EVAL score = score(name)
| SORT score DESC
| LIMIT 10
// 多字段匹配
FROM products
| WHERE name : "耳机" OR description : "降噪"
| KEEP name, price
| LIMIT 20
6.4 聚合分析
ES|QL 的 STATS 命令是聚合分析的核心,支持按字段分组并计算指标:
// 基础聚合
FROM products
| STATS
count = COUNT(*),
avg_price = AVG(price),
min_price = MIN(price),
max_price = MAX(price),
total_value = SUM(price)
BY category
| SORT avg_price DESC
// 多层聚合
FROM products
| WHERE create_time >= "2026-06-01"
| EVAL month = DATE_FORMAT("yyyy-MM", create_time)
| STATS
revenue = SUM(price),
items = COUNT(*)
BY month, category
| SORT month ASC, revenue DESC
// 使用 sparkline 生成迷你图表(9.4 新增)
FROM products
| STATS price_trend = sparkline(price) BY category
| KEEP category, price_trend
// 使用 LIMIT BY 限制每组行数(9.4 Tech Preview)
FROM products
| SORT price DESC
| LIMIT 3 BY category
ES|QL 聚合函数一览:
| 函数 | 说明 |
|---|---|
COUNT(*) |
行计数 |
COUNT(field) |
非空值计数 |
SUM(field) |
求和 |
AVG(field) |
平均值 |
MIN(field) / MAX(field) |
最小值/最大值 |
MEDIAN(field) |
中位数 |
PERCENTILE(field, p) |
百分位数 |
STD_DEV(field) |
标准差 |
VAR_SAMP(field) |
样本方差 |
cardinality(field) |
去重计数 |
sparkline(field) |
迷你直方图 |
COUNT_DISTINCT(field) |
精确去重计数 |
6.5 ES|QL Views(9.4 新特性)
9.4 引入了 Views 功能——将一段 ES|QL 查询封装为虚拟索引,外部可以像查询物理索引一样引用它:
-- 创建视图:标准化原始日志
CREATE VIEW clean_logs AS
FROM raw-logs-*
| RENAME @timestamp AS ts, host.name AS host
| EVAL level = UPPER(log.level)
| WHERE level != "DEBUG"
| KEEP ts, host, level, message;
-- 像查询索引一样查询视图
FROM clean_logs
| STATS count = COUNT(*) BY host
| SORT count DESC
| LIMIT 10
-- 视图可以与物理索引混合查询
FROM clean_logs, alerts-*
| WHERE level == "ERROR"
| KEEP ts, host, message, alert_type
| SORT ts DESC
| LIMIT 50
Views 的安全限制:当底层索引启用了文档级安全(DLS)或字段级安全(FLS)时,视图无法被查询。这个限制在 ES 安全层强制执行。在混合版本跨集群搜索(CCS)场景中,也需要特别注意视图解析的兼容性。
6.6 时间序列查询
9.4 为 ES|QL 增加了 TS 源命令和 METRICS_INFO、TS_INFO 等时间序列内省命令:
// 查看数据流中的指标列表
TS k8s-metrics
| METRICS_INFO
| WHERE metric_type == "counter"
| SORT metric_name
// 查看每个时间序列的维度
TS k8s-metrics
| TS_INFO
| SORT metric_name, dimensions
// 计算速率(counter rate)
TS k8s-metrics
| STATS avg_rate = AVG(RATE(network.bytes, 5m)) BY TBUCKET(10m), host
| SORT host, TBUCKET(10m)
// 9.4 新增:窗口大小不必是 bucket 的整数倍
TS k8s-metrics
| STATS AVG(RATE(requests, 15m)) BY TBUCKET(10m), host
6.7 数据解析与转换
ES|QL 强大的地方在于数据解析能力,特别适合日志分析场景:
// GROK 解析非结构化日志
FROM nginx-logs
| GROK message "%{IP:client_ip} - %{DATA:user} \[%{TIMESTAMP_ISO8601:ts}\] \"%{WORD:method} %{URIPATH:path} %{DATA:protocol}\" %{NUMBER:status} %{NUMBER:bytes}"
| KEEP client_ip, method, path, status, bytes
| WHERE status >= 400
| SORT ts DESC
| LIMIT 20
// DISSECT 解析结构化日志(比 GROK 快)
FROM app-logs
| DISSECT message "%{service} [%{level}] %{timestamp} %{msg}"
| EVAL level = UPPER(level)
| WHERE level == "ERROR"
// JSON 提取
FROM events
| EVAL user_agent = JSON_EXTRACT(headers, "user-agent")
| EVAL ip = JSON_EXTRACT(request, "remote_addr")
// 9.4 新增函数
FROM web-logs
| USER_AGENT user_agent // 解析 UA 为结构化字段
| REGISTERED_DOMAIN host // 提取注册域名
| URI_PART url // 提取 URI 各部分
6.8 ES|QL 函数大全
6.8.1 字符串函数
| 函数 | 说明 | 示例 |
|---|---|---|
CONCAT(a, b) |
拼接字符串 | CONCAT(first, " ", last) |
UPPER(s) / LOWER(s) |
大小写转换 | UPPER(level) |
LENGTH(s) |
字符串长度 | LENGTH(message) |
SUBSTRING(s, start, len) |
截取子串 | SUBSTRING(name, 1, 10) |
TRIM(s) |
去除首尾空白 | TRIM(input) |
REPLACE(s, pattern, repl) |
正则替换 | REPLACE(phone, "\\D", "") |
SPLIT(s, sep) |
分割为多值 | SPLIT(tags, ",") |
LEFT(s, n) / RIGHT(s, n) |
左/右截取 | LEFT(name, 3) |
6.8.2 日期函数
| 函数 | 说明 | 示例 |
|---|---|---|
NOW() |
当前时间 | NOW() |
DATE_FORMAT(fmt, date) |
格式化日期 | DATE_FORMAT("yyyy-MM", @timestamp) |
DATE_TRUNC(interval, date) |
时间截断 | DATE_TRUNC(1 hour, @timestamp) |
DATE_EXTRACT(field, date) |
提取日期部分 | DATE_EXTRACT("hour", @timestamp) |
TO_DATE(s) |
字符串转日期 | TO_DATE("2026-07-04") |
6.8.3 数学函数
| 函数 | 说明 |
|---|---|
ABS(x) |
绝对值 |
CEIL(x) / FLOOR(x) |
向上/向下取整 |
ROUND(x, n) |
四舍五入 |
SQRT(x) |
平方根 |
POW(x, y) |
幂运算 |
LOG(x) / LN(x) |
对数 |
GREATEST(a, b) / LEAST(a, b) |
最大/最小值 |
6.8.4 多值函数
| 函数 | 说明 |
|---|---|
MV_EXPAND(field) |
将多值字段展开为多行 |
MV_UNION(a, b) |
合并多值(9.4 新增) |
MV_INTERSECTS(a, b) |
交集(9.4 新增) |
MV_DIFFERENCE(a, b) |
差集(9.4 新增) |
MV_COUNT(field) |
多值字段元素数 |
MV_MAX(field) / MV_MIN(field) |
多值字段最大/最小值 |
第七章 向量搜索与语义检索
利用 kNN 搜索和 semantic_text 构建 AI 驱动的语义检索系统。
7.1 向量搜索基础
传统全文搜索基于关键词匹配,无法理解语义——搜索"手机"时找不到文档中只写了"智能手机"的结果。向量搜索通过将文本编码为高维向量,在向量空间中计算相似度,实现语义级别的匹配。
ElasticSearch 支持两种向量搜索方式:
dense_vector字段类型:存储预计算的向量,适合需要精细控制的场景semantic_text字段类型:自动完成嵌入计算和向量存储,最简单的方式
9.4 中,semantic_text 默认使用 BFLOAT16 量化与 bbq_disk 存储,TEXT_EMBEDDING 和 RERANK 均已正式 GA。
向量搜索的写入与查询路径:
写入路径:
原始文档 → 嵌入模型(text-embedding) → 向量(dense_vector) → 量化(bbq_disk) → HNSW 索引
查询路径:
查询文本 → 嵌入模型(相同模型) → 查询向量 → kNN 搜索(HNSW + 量化) → Top-K 结果
7.2 使用 semantic_text
semantic_text 是最简单的向量搜索方式——只需声明字段类型,ElasticSearch 自动调用配置好的推理端点完成嵌入计算:
// 1. 创建推理端点(使用内置模型或外部 API)
PUT _inference/text_embedding/my-embedding
{
"service": "openai",
"service_settings": {
"model_id": "text-embedding-3-small",
"api_key": "sk-..."
}
}
// 2. 创建索引,使用 semantic_text 字段
PUT /knowledge-base
{
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"inference_id": "my-embedding"
},
"title": { "type": "text" },
"category": { "type": "keyword" }
}
}
}
// 3. 写入文档(自动生成向量)
POST /knowledge-base/_doc
{
"title": "ElasticSearch 性能调优",
"content": "通过调整分片数量和映射配置可以显著提升查询性能...",
"category": "技术"
}
// 4. 语义搜索
GET /knowledge-base/_search
{
"query": {
"semantic": {
"field": "content",
"query": "如何优化搜索速度"
}
}
}
写入时自动调用嵌入模型生成向量并存储,查询时同样自动将查询文本编码为向量执行 kNN 搜索。整个过程对开发者透明,无需手动管理向量。
使用 Elastic 内置模型(ELSER):
// 部署 ELSER 模型
PUT _ml/trained_models/.elser_model_2
{
"description": "ELSER v2 model"
}
// 启动模型部署
POST _ml/trained_models/.elser_model_2/deployment/_start?wait_for=starting
// 创建推理端点
PUT _inference/text_embedding/elser-endpoint
{
"service": "elser",
"service_settings": {
"num_allocations": 1,
"num_threads": 4
}
}
// 使用 ELSER 的 semantic_text
PUT /knowledge-base-elser
{
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"inference_id": "elser-endpoint"
}
}
}
}
ELSER(Elastic Learned Sparse EncodeR)是 Elastic 自研的稀疏向量模型,不需要外部 API,在 ElasticSearch 集群内运行。
7.3 手动 dense_vector 与 kNN
需要更精细控制时,可以手动管理 dense_vector 字段:
PUT /articles-vector
{
"mappings": {
"properties": {
"title": { "type": "text" },
"embedding": {
"type": "dense_vector",
"dims": 1536,
"index": true,
"similarity": "cosine",
"index_options": {
"type": "bbq_disk",
"m": 16,
"ef_construction": 100
}
}
}
}
}
// kNN 查询
GET /articles-vector/_search
{
"knn": {
"field": "embedding",
"query_vector": [0.1, 0.2, /* 1536 维向量 */],
"k": 10,
"num_candidates": 100
},
"_source": ["title"]
}
HNSW 参数详解:
| 参数 | 默认值 | 说明 |
|---|---|---|
type |
bbq_disk(9.4 默认) |
量化类型:hnsw(无量化)、bbq_disk、bbq_memory |
m |
16 | HNSW 图中每个节点的最大连接数。越大精度越高但内存越多 |
ef_construction |
100 | 构建时的探索因子。越大索引质量越高但构建越慢 |
confidence_interval |
- | 量化误差的置信区间控制 |
k 是最终返回的近邻数量,num_candidates 是每个分片上探索的候选数量(影响精度与性能的权衡)。9.4 中 bbq_disk 成为默认的量化类型。
相似度度量:
| 度量 | 说明 | 适用场景 |
|---|---|---|
cosine |
余弦相似度 | 文本嵌入(最常用) |
dot_product |
点积 | 已归一化的向量 |
l2_norm / max_inner_product |
欧氏距离/最大内积 | 特定模型要求 |
7.4 混合搜索
纯向量搜索可能遗漏精确关键词匹配的结果,纯全文搜索可能遗漏语义相关但用词不同的结果。混合搜索将两者结合:
GET /knowledge-base/_search
{
"query": {
"bool": {
"should": [
{
"semantic": {
"field": "content",
"query": "如何优化搜索速度"
}
},
{
"match": {
"title": "性能 调优 优化"
}
}
]
}
},
"size": 10
}
混合查询会在 should 子句中同时计算向量相似度得分和 BM25 文本得分,两者加权融合后排序。混合搜索相比纯 BM25 搜索,"找不到明显结果"的用户投诉可降低 70-85%,代价是每查询增加约 5-15ms 延迟。
使用 RRF(Reciprocal Rank Fusion)融合:
GET /knowledge-base/_search
{
"size": 10,
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"semantic": {
"field": "content",
"query": "如何优化搜索速度"
}
}
}
},
{
"standard": {
"query": {
"match": {
"title": "性能 调优 优化"
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 60
}
}
}
RRF 是一种无需调参的排名融合方法,通过倒数排名加权合并多个查询结果,在混合搜索中表现稳定。
7.5 RAG 重排序
9.4 中 RERANK 命令正式 GA。在 kNN 初检后使用重排序模型对候选结果做二次精排:
// 先用 kNN 取 50 个候选,再用 rerank 精排取 top 10
GET /knowledge-base/_search
{
"size": 10,
"knn": {
"field": "content.embedding",
"query_vector_builder": {
"text_embedding": {
"model_id": "my-embedding",
"model_text": "如何优化搜索速度"
}
},
"k": 50,
"num_candidates": 500
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"text_expansion": {
"content": {
"model_id": ".elser_model_2",
"model_text": "如何优化搜索速度"
}
}
}
}
}
}
这种两阶段检索(粗排 + 精排)是 RAG 系统的标准模式:
- 粗排阶段:用低延迟的向量搜索获取候选集
- 精排阶段:用更精确的模型对候选集重新打分
在延迟和质量之间取得平衡。
7.6 向量搜索性能优化
7.6.1 量化选择
| 量化类型 | 精度 | 速度 | 存储 | 适用场景 |
|---|---|---|---|---|
hnsw(无量化) |
最高 | 中 | 最大 | 对精度要求极高,小规模数据 |
bbq_disk(9.4 默认) |
高 | 快 | 小 60-70% | 通用场景,推荐 |
bbq_memory |
高 | 最快 | 小 60-70% | 内存充足,追求极致延迟 |
| 1-bit 量化 | 低 | 最快 | 最小 | 大规模粗排 |
// 配置量化位深度(9.4 新增)
{
"properties": {
"embedding": {
"type": "dense_vector",
"dims": 1536,
"index_options": {
"type": "bbq_disk",
"config": {
"bits": 4 // 可选 1, 2, 4, 7
}
}
}
}
}
7.6.2 过滤优化
kNN 查询支持 filter 参数,在向量搜索前先过滤候选集。9.4 的 DiskBBQ 算法在带限制性过滤的场景下性能提升 3 倍以上:
// 带过滤的 kNN 查询
{
"knn": {
"field": "embedding",
"query_vector": [/* ... */],
"k": 10,
"num_candidates": 100,
"filter": {
"bool": {
"filter": [
{ "term": { "category": "技术" } },
{ "range": { "publish_date": { "gte": "2026-01-01" } } }
]
}
}
}
}
7.6.3 GPU 加速(9.4 GA)
9.4 中 GPU 向量索引正式 GA,通过集成 NVIDIA cuVS 实现:
# elasticsearch.yml 配置
node.attr.ml.gpu: true
GPU 加速效果:
- 索引吞吐提升 12 倍
- force merge 快 7 倍
- 适合大规模向量索引场景(亿级以上文档)
第八章 性能调优深度实战
从 JVM 堆内存到查询缓存,系统性地调优集群性能。
8.1 JVM 堆内存调优
ElasticSearch 运行在 JVM 上,堆内存配置是最基础也最关键的调优项。核心原则:堆内存不超过物理内存的 50%,且不超过 31 GB(压缩指针的阈值)。
| 配置项 | 推荐值 | 说明 |
|---|---|---|
-Xms 和 -Xmx |
相同值,设为物理内存的 50% | 避免堆动态扩缩导致的停顿 |
| 堆内存上限 | ≤ 31 GB | 超过 31 GB 无法使用压缩指针,内存效率下降 |
| 堆外内存 | 留给 Lucene 文件系统缓存 | Lucene 依赖 OS 页缓存加速 Segment 读取 |
| GC 算法 | G1GC(JDK 21+ 默认) | ElasticSearch 9.x 内置 JDK 21,G1GC 适合大堆 |
# jvm.options 配置
-Xms16g
-Xmx16g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:G1ReservePercent=25
# 或通过环境变量
ES_JAVA_OPTS="-Xms16g -Xmx16g -XX:+UseG1GC"
堆内存不是越大越好:超过 31 GB 后,JVM 无法使用压缩指针(Compressed OOPs),每个对象引用从 4 字节变为 8 字节,实际有效内存反而下降。更重要的是,Lucene 依赖操作系统的文件系统缓存来加速 Segment 的读取——如果堆占满物理内存,Lucene 的随机读取将退化为磁盘 I/O,查询性能断崖式下降。留 50% 物理内存给 OS 缓存是铁律。
JVM 调优检查清单:
- [ ]
-Xms和-Xmx设置为相同值 - [ ] 堆内存不超过 31 GB
- [ ] 堆内存不超过物理内存的 50%
- [ ] 使用 G1GC(9.x 默认)
- [ ] 监控 GC 频率和停顿时间
- [ ] 确认使用压缩指针(日志中有
Compressed ordinary object pointers)
8.2 查询性能调优
8.2.1 filter 缓存与查询结构
filter 上下文的查询结果会被自动缓存为位图(bitmap),相同条件再次查询时直接命中缓存,跳过整个倒排索引扫描。关键是要确保过滤条件可缓存且重复使用。
// 好的做法:filter 中的条件稳定且可缓存
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "耳机" } }
],
"filter": [
{ "term": { "category": "数码" } },
{ "range": { "price": { "gte": 100, "lte": 2000 } } }
]
}
}
}
// 避免的做法:将不需要打分的条件放在 must 中
{
"query": {
"bool": {
"must": [
{ "match": { "name": "耳机" } },
{ "term": { "category": "数码" } }, // 浪费:不需要打分
{ "range": { "price": { "gte": 100 } } } // 浪费:不被缓存
]
}
}
}
哪些查询会被缓存:
term、terms、range在 filter 上下文中bool的filter和must_not子句- 使用
now/1d等舍入表达式的日期 range
哪些查询不会被缓存:
match、multi_match等 query 上下文查询- 使用
now精确到毫秒的日期 range script查询
8.2.2 避免脚本查询
script_score 和脚本聚合是性能杀手——每条匹配文档都需要执行脚本,无法利用索引结构。如果必须使用脚本,优先用 painless 并启用脚本缓存:
// 避免:script_score 全表扫描
{
"query": {
"script_score": {
"query": { "match_all": {} },
"script": { "source": "doc['popularity'].value * doc['recency'].value" }
}
}
}
// 替代方案:在写入时计算好排序字段
// 文档写入时增加 rank_score 字段
{ "name": "耳机", "rank_score": 8.5, "popularity": 100, "recency": 0.085 }
// 查询时直接用 function_score 或 sort
{
"query": { "match": { "name": "耳机" } },
"sort": [{ "rank_score": "desc" }]
}
必须使用脚本时的优化:
// 使用 script 的正确姿势
{
"query": {
"bool": {
"filter": [
{ "range": { "price": { "gte": 100 } } } // 先用 filter 缩小范围
]
}
},
"script_fields": {
"custom_score": {
"script": {
"source": "doc['popularity'].value * params.weight",
"params": { "weight": 1.5 } // 使用 params 避免编译
}
}
}
}
关键点:
- 先用 filter 缩小文档范围,再对结果执行脚本
- 使用
params传递参数,脚本源码会被编译缓存 - 避免
doc['field']访问text字段(无法访问分词后的值)
8.2.3 日期查询优化
对 date 字段做范围查询时,使用 now/1d 这样的舍入表达式可以利用查询缓存:
// 好:舍入到天,可缓存
{ "range": { "create_time": { "gte": "now/d", "lt": "now+1d/d" } } }
// 差:精确到毫秒,每次查询不同,不缓存
{ "range": { "create_time": { "gte": "2026-07-04T10:30:00.123Z" } } }
8.2.4 索引预排序
如果查询总是按某个字段排序(如时间倒序),可以在索引设置中启用 index.sort,写入时文档按指定字段排序存储,查询时 Lucene 可以提前终止扫描:
PUT /logs-app
{
"settings": {
"index.sort.field": ["@timestamp"],
"index.sort.order": ["desc"]
}
}
查询 sort @timestamp desc, size 10 时,Lucene 按已排序顺序读取文档,收集到 10 条后立即终止,无需扫描全部匹配文档。对于时间序列数据,这可以带来数量级的性能提升。
索引预排序的性能收益:
场景:10 亿条日志,查询最近 10 条
────────────────────────────────────
无预排序: ~3000 ms(扫描所有匹配文档后排序取 top 10)
有预排序: ~5 ms(按已排序顺序读取 10 条即终止)
提升: 600 倍
8.3 集群级调优
8.3.1 节点角色分离
生产集群建议将主节点、数据节点、协调节点分离部署:
# elasticsearch.yml 节点角色配置
# 专用主节点(3 个,保证选举多数)
node.roles: [master]
# 数据节点(根据数据温度细分)
node.roles: [data, data_content, data_hot, data_warm, data_cold]
# 协调节点(不存数据,只路由和合并)
node.roles: []
# ingest 节点(数据预处理)
node.roles: [ingest]
节点配置建议:
| 节点角色 | CPU | 内存 | 磁盘 | 说明 |
|---|---|---|---|---|
| master | 4 核 | 8 GB | 50 GB SSD | 只需存集群状态,配置不需要太高 |
| data_hot | 16+ 核 | 64 GB | 1-2 TB NVMe SSD | 高 IOPS,写入和查询负载重 |
| data_warm | 8 核 | 32 GB | 2-4 TB SSD | 中等性能,查询为主 |
| data_cold | 4 核 | 16 GB | 4-8 TB HDD | 低成本存储,偶尔查询 |
| coordinating | 8+ 核 | 16-32 GB | 100 GB | 需要内存做结果合并和聚合 |
| ingest | 4-8 核 | 8-16 GB | 100 GB | 执行 pipeline 预处理 |
8.3.2 线程池配置
// 查看线程池状态
GET /_cat/thread_pool?v&h=node_name,name,active,queue,rejected,completed
// 关键线程池
// search: 查询线程池,queue 满会拒绝查询请求
// write: 写入线程池,queue 满会拒绝写入请求
// merge: Segment 合并线程池
// 调整搜索线程池大小
PUT _cluster/settings
{
"transient": {
"thread_pool.search.queue_size": 2000,
"thread_pool.search.size": 20
}
}
rejected 指标:当线程池的 active 线程数达到上限且 queue 满时,新请求会被 rejected。持续增长 的 rejected 数表明集群负载过高,需要扩容或优化查询。
8.3.3 熔断器配置
ElasticSearch 有多层熔断器防止 OOM:
| 熔断器 | 默认阈值 | 说明 |
|---|---|---|
parent |
95% | 总堆使用率上限 |
fielddata |
40% | fielddata 缓存上限 |
request |
60% | 单请求内存上限 |
in_flight_requests |
100% | 进行中请求内存上限 |
script_compilation |
75/5min | 5 分钟内脚本编译数上限 |
// 调整熔断器
PUT _cluster/settings
{
"transient": {
"indices.breaker.total.limit": "70%",
"indices.breaker.fielddata.limit": "40%",
"indices.breaker.request.limit": "60%"
}
}
8.4 监控与诊断
8.4.1 关键监控 API
| API | 用途 | 关键指标 |
|---|---|---|
_cluster/health |
集群健康状态 | status、number_of_nodes、unassigned_shards |
_cat/indices?v |
索引概览 | docs.count、store.size、health |
_cat/shards?v |
分片分布 | shard、prirep、state、node |
_nodes/stats |
节点统计 | jvm.mem、thread_pool、indices.search |
_cat/thread_pool?v |
线程池状态 | active、queue、rejected |
_search/profile |
查询性能分析 | time_in_nanos、breakdown |
_cat/allocation?v |
磁盘使用 | disk.used、disk.percent |
_nodes/hot_threads |
热点线程 | CPU 占用高的线程 |
8.4.2 慢查询日志
// 开启慢查询日志
PUT /products/_settings
{
"index.search.slowlog.threshold.query.warn": "2s",
"index.search.slowlog.threshold.query.info": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "200ms",
"index.indexing.slowlog.threshold.index.warn": "1s",
"index.indexing.slowlog.threshold.index.info": "200ms"
}
慢查询日志记录超过阈值的查询详情,是发现性能问题的第一手段。配合 _search/profile 可以精确定位到是哪个子查询慢、是否命中缓存、扫描了多少文档。
慢查询日志示例:
[2026-07-04T10:30:15,123][WARN][index.search.slowlog.query] [node-1] [products][0] took[1.5s], took_millis[1500], total_hits[1000000], types[], stats[], search_type[QUERY_THEN_FETCH], total_shards[3], source[{"query":{"bool":{"must":[{"match":{"name":{"query":"耳机"}}}]}}}],
8.4.3 热点线程分析
当节点 CPU 使用率异常时,使用 hot_threads API 定位问题:
# 获取热点线程
GET /_nodes/hot_threads?threads=10&interval=500ms&snapshots=10
# 输出示例
# node-1
# 85.3% [cpu] com.elasticsearch.search.SearchService.executeQuery()
# 10.2% [cpu] org.apache.lucene.search.BooleanQuery$BooleanWeight.scorer()
# 4.5% [cpu] com.lucene.index.SegmentReader.document()
8.5 常见性能问题排查
8.5.1 查询慢的排查流程
查询慢
│
├── 是否深度分页?
│ ├── 是 → 改用 search_after / PIT
│ └── 否 ↓
│
├── filter 是否在 must 中?
│ ├── 是 → 移到 filter 子句
│ └── 否 ↓
│
├── 是否有脚本查询?
│ ├── 是 → 预计算字段替代脚本
│ └── 否 ↓
│
├── 聚合是否高基数?
│ ├── 是 → 用 composite 或 cardinality
│ └── 否 ↓
│
├── Segment 数量是否过多?
│ ├── 是 → force merge 只读索引
│ └── 否 ↓
│
├── 是否使用 profile 定位?
│ └── 使用 _search?profile=true 找到最慢子查询
│
└── 检查集群负载
├── GC 停顿是否频繁 → 调整 JVM
├── 磁盘 I/O 是否饱和 → 增加 hot 节点
└── 线程池 rejected 是否高 → 扩容或优化
8.5.2 写入慢的排查流程
写入慢
│
├── refresh_interval 是否过短?
│ └── 批量写入时设为 -1 或 30s
│
├── Bulk 批次是否太小?
│ └── 调整到 5-15 MB
│
├── 副本同步是否成为瓶颈?
│ └── 批量导入时临时设为 0
│
├── Segment 合并是否落后?
│ └── 检查 _cat/segments,调整合并策略
│
├── translog 是否过大?
│ └── 检查 index.translog.flush_threshold_size
│
└── 检查磁盘 I/O
└── SSD vs HDD,IOPS 是否充足
8.5.3 常见问题速查表
| 症状 | 可能原因 | 解决方案 |
|---|---|---|
| 查询偶尔超时 | GC 停顿 | 检查 JVM 堆使用率,调整 GC |
| 聚合 OOM | 高基数聚合 | 用 composite 分页或 cardinality |
| 写入 rejected | write 线程池满 | 扩容 data 节点或优化批量大小 |
| 集群状态 yellow | 副本未分配 | 检查节点数量和磁盘水位 |
| 搜索结果不全 | 分片故障 | 检查 _cluster/health 和 _cat/shards |
| 磁盘只读 | 超过 flood_stage | 清理数据或增加磁盘,手动解除只读 |
| CPU 飙高 | 合并或查询风暴 | 检查 hot_threads,限制合并线程 |
| 内存增长不释放 | fielddata 缓存 | 限制 fielddata 断路器 |
第九章 生产级实战案例
将前面学到的知识综合应用到电商搜索和日志分析两个典型场景。
9.1 电商搜索系统
电商搜索是 ElasticSearch 最典型的应用场景,需要同时满足相关性、性能和业务规则的需求。
9.1.1 索引设计
PUT /ecommerce
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"refresh_interval": "1s",
"analysis": {
"analyzer": {
"pinyin_analyzer": {
"tokenizer": "pinyin_tokenizer"
}
},
"tokenizer": {
"pinyin_tokenizer": {
"type": "pinyin",
"keep_first_letter": true,
"keep_full_pinyin": true,
"lowercase": true
}
}
}
},
"mappings": {
"properties": {
"product_id": { "type": "keyword" },
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": { "type": "keyword", "ignore_above": 256 },
"pinyin": { "type": "text", "analyzer": "pinyin_analyzer" },
"completion": { "type": "completion" }
}
},
"price": { "type": "scaled_float", "scaling_factor": 100 },
"category": { "type": "keyword" },
"brand": { "type": "keyword" },
"tags": { "type": "keyword" },
"sales_count": { "type": "integer" },
"rating": { "type": "float" },
"status": { "type": "keyword" },
"create_time": { "type": "date" },
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
这个映射实现了多维度搜索能力:名称支持中文分词(IK)、拼音搜索和自动补全;价格为 scaled_float 避免精度问题;分类、品牌、标签为 keyword 支持精确过滤和聚合。
9.1.2 搜索查询实现
GET /ecommerce/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "蓝牙耳机",
"fields": ["name^5", "name.pinyin^3", "description^1"],
"type": "best_fields",
"minimum_should_match": "70%"
}
}
],
"should": [
{ "term": { "tags": "热销" } },
{ "range": { "rating": { "gte": 4.5 } } }
],
"filter": [
{ "term": { "status": "on_sale" } },
{ "range": { "price": { "gte": 50, "lte": 3000 } } }
],
"minimum_should_match": 0
}
},
"functions": [
{
"filter": { "range": { "sales_count": { "gte": 1000 } } },
"weight": 1.5
}
],
"sort": [
{ "_score": "desc" },
{ "sales_count": "desc" },
{ "create_time": "desc" }
],
"aggs": {
"categories": { "terms": { "field": "category", "size": 10 } },
"brands": { "terms": { "field": "brand", "size": 10 } },
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 100 },
{ "from": 100, "to": 500 },
{ "from": 500, "to": 1000 },
{ "from": 1000 }
]
}
}
},
"size": 20
}
这个查询同时实现了:
- 多字段加权搜索(名称权重最高,拼音次之,描述最低)
- 状态和价格过滤(走缓存)
- 热销标签和评分加权提升
- 销量和时间的多级排序
- 分类/品牌/价格区间的聚合面(用于搜索结果页的筛选器)
9.1.3 搜索补全实现
// 搜索补全查询
GET /ecommerce/_search
{
"suggest": {
"product-suggest": {
"prefix": "蓝",
"completion": {
"field": "name.completion",
"size": 10,
"skip_duplicates": true
}
}
}
}
// 同时返回搜索结果和补全建议
GET /ecommerce/_search
{
"query": { "match_all": {} },
"suggest": {
"product-suggest": {
"prefix": "蓝牙",
"completion": {
"field": "name.completion",
"size": 5
}
}
},
"size": 0
}
9.1.4 定时同步与更新
# Python 示例:从数据库同步商品到 ElasticSearch
import psycopg2
from elasticsearch import Elasticsearch, helpers
es = Elasticsearch(["http://localhost:9200"])
pg = psycopg2.connect("dbname=shop user=postgres")
def sync_products():
cursor = pg.cursor()
cursor.execute("""
SELECT id, name, price, category, brand, tags, sales_count,
rating, status, create_time, description
FROM products
WHERE update_time > NOW() - INTERVAL '1 hour'
""")
actions = []
for row in cursor:
action = {
"_index": "ecommerce",
"_id": row[0],
"_source": {
"product_id": row[0],
"name": row[1],
"price": row[2],
"category": row[3],
"brand": row[4],
"tags": row[5],
"sales_count": row[6],
"rating": row[7],
"status": row[8],
"create_time": row[9],
"description": row[10],
"name_completion": {
"input": [row[1], row[1].split()],
"weight": row[6] # 按销量设置权重
}
}
}
actions.append(action)
helpers.bulk(es, actions, chunk_size=500)
print(f"Synced {len(actions)} products")
9.2 日志分析平台
日志分析是 ElasticSearch 另一个核心场景。
9.2.1 索引模板设计
PUT _index_template/app-logs
{
"index_patterns": ["app-logs-*"],
"data_stream": {},
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"index.lifecycle.name": "logs-policy",
"index.refresh_interval": "1s",
"index.mapping.total_fields.limit": 2000,
"index.sort.field": ["@timestamp"],
"index.sort.order": ["desc"]
},
"mappings": {
"dynamic": "true",
"dynamic_templates": [
{
"strings_as_keyword": {
"match_mapping_type": "string",
"mapping": { "type": "keyword", "ignore_above": 512 }
}
}
],
"properties": {
"@timestamp": { "type": "date" },
"level": { "type": "keyword" },
"service": { "type": "keyword" },
"host": { "type": "keyword" },
"message": { "type": "text", "analyzer": "standard" },
"trace_id": { "type": "keyword" },
"duration_ms": { "type": "integer" }
}
}
}
}
9.2.2 使用 ES|QL 分析日志
// 按服务统计错误率和 P99 延迟
FROM app-logs
| WHERE @timestamp >= NOW() - 1 hours
| STATS
total = COUNT(*),
errors = COUNT(WHERE level == "ERROR"),
error_rate = errors * 100.0 / total,
p99_latency = PERCENTILE(duration_ms, 99),
avg_latency = AVG(duration_ms)
BY service
| SORT error_rate DESC
// 查找慢请求的调用链
FROM app-logs
| WHERE duration_ms > 1000 AND level != "DEBUG"
| KEEP @timestamp, service, trace_id, message, duration_ms
| SORT duration_ms DESC
| LIMIT 50
// 错误趋势分析
FROM app-logs
| WHERE level == "ERROR" AND @timestamp >= NOW() - 24 hours
| EVAL hour = DATE_TRUNC(1 hour, @timestamp)
| STATS error_count = COUNT(*) BY hour, service
| SORT hour ASC, service
// Top 10 错误消息
FROM app-logs
| WHERE level == "ERROR"
| STATS count = COUNT(*) BY message
| SORT count DESC
| LIMIT 10
9.2.3 告警查询
// 使用 Kibana Alerting 配置告警条件
GET /app-logs/_search
{
"size": 0,
"query": {
"bool": {
"filter": [
{ "range": { "@timestamp": { "gte": "now-5m/m" } } },
{ "terms": { "level": ["ERROR", "FATAL"] } }
]
}
},
"aggs": {
"by_service": {
"terms": { "field": "service", "size": 20 },
"aggs": {
"error_count": { "value_count": { "field": "@timestamp" } },
"sample_messages": {
"top_hits": {
"size": 3,
"_source": ["message", "trace_id"],
"sort": [{ "@timestamp": "desc" }]
}
}
}
}
}
}
这个告警查询在最近 5 分钟内按服务分组统计错误数,并附带 3 条最新错误消息的样本。配合 Kibana Alerting 可以在错误数超过阈值时触发通知。
9.2.4 使用 Ingest Pipeline 预处理日志
// 创建 Ingest Pipeline
PUT _ingest/pipeline/app-logs-pipeline
{
"description": "应用日志预处理",
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{TIMESTAMP_ISO8601:log_time} \\[%{LOGLEVEL:level}\\] \\[%{DATA:service}\\] \\[%{DATA:trace_id}\\] %{GREEDYDATA:msg}"
]
}
},
{
"date": {
"field": "log_time",
"formats": ["ISO8601"],
"target_field": "@timestamp"
}
},
{
"convert": {
"field": "duration_ms",
"type": "integer",
"ignore_missing": true
}
},
{
"script": {
"source": """
if (ctx.duration_ms != null && ctx.duration_ms > 2000) {
ctx.slow_request = true;
}
"""
}
},
{
"remove": {
"field": "log_time",
"ignore_missing": true
}
}
],
"on_failure": [
{
"set": {
"field": "error.message",
"value": "Pipeline failed: {{ _ingest.on_failure_message }}"
}
}
]
}
// 在索引设置中指定默认 pipeline
PUT _component_template/app-logs-pipeline
{
"template": {
"settings": {
"index.default_pipeline": "app-logs-pipeline"
}
}
}
9.3 多集群与跨集群搜索
对于大规模部署,可以使用跨集群搜索(CCS)在多个集群上执行查询:
// 配置远程集群
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_east": {
"seeds": ["east-node1:9300", "east-node2:9300"]
},
"cluster_west": {
"seeds": ["west-node1:9300", "west-node2:9300"]
}
}
}
}
}
// 跨集群搜索
GET /cluster_east:logs-*,cluster_west:logs-*/_search
{
"query": {
"bool": {
"filter": [
{ "range": { "@timestamp": { "gte": "now-1h" } } },
{ "term": { "level": "ERROR" } }
]
}
},
"size": 50
}
// 跨集群 ES|QL 查询
POST /_query
{
"query": """
FROM cluster_east:app-logs, cluster_west:app-logs
| WHERE level == "ERROR" AND @timestamp >= NOW() - 1 hours
| STATS error_count = COUNT(*) BY service
| SORT error_count DESC
"""
}
9.4 安全配置
生产环境的安全配置清单:
# elasticsearch.yml
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.http.ssl.enabled: true
# 生成证书
# elasticsearch-certutil ca
# elasticsearch-certutil cert --ca elastic-stack-ca.p12
# 创建用户和角色
// 创建自定义角色
POST /_security/role/logs_reader
{
"indices": [
{
"names": ["app-logs-*"],
"privileges": ["read", "view_index_metadata"]
}
]
}
// 创建用户
POST /_security/user/log_viewer
{
"password": "secure_password",
"roles": ["logs_reader"],
"full_name": "Log Viewer"
}
// 创建 API Key(推荐用于服务间认证)
POST /_security/api_key
{
"name": "log-collector",
"role_descriptors": {
"log_writer": {
"indices": [
{
"names": ["app-logs-*"],
"privileges": ["write", "create_doc", "create_index"]
}
]
}
}
}
9.5 学习路径总结
入门 进阶 高级 优化 专家 生产
│ │ │ │ │ │
├─ 概念+CRUD ├─ 映射+DSL ├─ 聚合+分页 ├─ 索引+查询调优 ├─ ES|QL+向量搜索 ├─ 集群运维+监控
├─ 倒排索引 ├─ 分析器+分词 ├─ 管道聚合 ├─ JVM 调优 ├─ 混合搜索 ├─ 安全配置
├─ 分片+副本 ├─ 动态模板 ├─ PIT+search_after├─ Segment 合并 ├─ RAG 重排序 ├─ 跨集群搜索
└─ REST API └─ nested/join └─ composite 聚合 └─ 索引预排序 └─ GPU 加速 └─ ILM 冷热分层
本教程覆盖了从入门到生产的完整路径。掌握索引映射设计、查询 DSL 编写和性能调优是三个最核心的能力——映射决定了数据的存储效率和功能边界,DSL 决定了查询的表达能力和性能表现,调优则决定了系统能否在生产负载下稳定运行。ES|QL 和向量搜索代表了 ElasticSearch 的未来方向,值得持续投入学习。
参考资料
- Elasticsearch 9.4 Release Notes - https://www.elastic.co/docs/release-notes/elasticsearch
- Elasticsearch 9.4 What’s New - https://versionlog.com/elasticsearch/9.4/
- Elastic Documentation - Tune for search speed - https://www.elastic.co/docs/deploy-manage/production-guidance/optimize-performance/search-speed
- Elastic Documentation - Tune for disk usage - https://www.elastic.co/docs/deploy-manage/production-guidance/optimize-performance/disk-usage
- Elastic Documentation - ES|QL reference - https://www.elastic.co/docs/reference/query-languages/esql
- Elastic Documentation - Dense vector field type - https://www.elastic.co/docs/reference/elasticsearch/mapping-reference/dense-vector
- Elastic Search Labs - Elasticsearch sizing best practices - https://www.elastic.co/search-labs/kr/blog/elasticsearch-node-shard-size-best-practices